00:04
Yeah, welcome everybody. This session is on running modern databases on Kubernetes and affectionately titled No More Dinosaur B VA S. Uh My name is Eric Shanks. I'm a technical marketing engineer for, for uh port works by pure storage and I'm accompanied by Pasha again, part of the technical marketing team uh inside the cloud native business unit or the port
00:27
works business unit at pure storage. If you're interested, you can find us on Twitter there on our Twitter is our, our Twitter handles and we'll get started. So let's take a look at what a traditional DB A uh tasks used to be, right? So the old office space thing, what would you
00:44
say you do here? Um First things we always, we, we're expecting a DB A to do is installing database engines, right? We're deploying mysql, we're just deploying oracle, we're deploying servers. In some cases, we have to, we have to handle performance tuning of the database instances themselves,
01:02
which includes re indexing databases and optimizing the databases on discs. I'll get into in a minute uh ensuring data recover ability, right? Somebody's got to make sure that the data in the database is can be recovered when someone goofs up one of their, their applications or uh a sequel command that accidentally deletes tables and things we have
01:21
to tune and test disaster recovery procedures. System administrators typically can't do all of this on their own. They need help from the database administrators for that replication and making sure that everything is available in our secondary sites capacity planning. Of course, license management specifically for SQL and oracle patching and upgrade the list kind of goes on and on,
01:42
right. The traditional database administrator used to run one of two apps, sequel or oracle. If you went to a conference and someone told you, hey, I'm a DB A. The second question was sequel or oracle. That's not necessarily the case anymore. But traditionally, this was the way it was and the roles of those database administrators have
02:03
changed quite a bit. So, um when I was a system administrator, I worked very closely with our database administrators and the things we, the typical things we had to do or the things we were really focused on with the data, data, database administrator um was aligning the database to a set of disks on a storage array or on a server, right? You'd have to put the database itself on a raid
02:24
group and you'd have to have a certain number of spindles to make sure that you got the performance out of that database. The same thing would happen with your transaction logs, which might have to have even faster uh discs or more spindles. And then of course, you put tempt B or something on another raid group. And then of course, you would have to have a way to replicate that data to ad R site.
02:42
So a lot of times you'd have a consistency group that had to work with the, the, the two raid groups for your database. So you could get that to your secondary site. This was uh a tedious process. In fact, we got to the point where in many cases to get the performance out of our databases, we had to do silly things like short stroking a disc.
03:01
Do we have any database administrators in here? Anybody has ever actually short stroked a disc or I know what I'm talking about, man. I'm starting to sound old, I think. Um So when we had traditional spinning discs, right? Uh we can only get IOP or more performance out of those disc in a few ways.
03:18
We had to either add more discs and spread the load out across those discs because they only spun at a certain rate. But in order to get more eye out out of those things, what we used to do is shrink the capacity of a disc. So if I had 100 gigabyte disk, I might only use 20 gigabytes of that disk and make sure that they're all in the same sectors
03:36
so that the read right head that was moving back and forth across the disc had less to move. So it didn't have to go back and forth as far and you had lower latency so you'd reduce the capacity that you had on disc just so you could get more performance out of those discs for your databases. Thankfully, I don't think anyone ever has to do this anymore. Right. But these are the silly things we used to do
03:58
with as database administrators but things changed just like uh here who had to evolve in a charm. Um We got better things, things have changed uh pretty dramatically, technology changed. We have flash now, right? We don't have to worry about managing spinning discs as much. So we're not spending as much time laying out
04:21
our database on SAN or on your local discs. Cloud computing happened. So now a lot of times database administrators are actually requesting a managed service in some cases from a cloud vendor. So just that means that the role of a database administrator has drastically changed. We've we've increased the amount of data that we are ingesting for all of our applications,
04:44
whether that's logs or just information about our customers. It could be lots of things we're collecting more metadata than ever. So this big data has a has had a huge impact on the way databases are created. In fact, it's even spun up new types of databases like a no SQL database as opposed to a more traditional relational database, we've got an increased emphasis on data
05:08
security and privacy. Obviously, we hear about hacks that happen all the time. Database administrators are one of the frontline defenders of making sure that that data isn't leaked out some place, making sure that encryption happens. And and so forth, popularity of micro services has dramatically changed the way databases uh database
05:25
administrators have worked and I'm going to get into that in a, in a minute. Um We've introduced automation and agile processes and things like that. So the way we used to manage databases is a lot different than it is. Now. Now we focused on things like agility.
05:38
How can we make our databases more easily used? Uh How can we deploy them faster? How can we move them from one cloud to another cloud or on prem to cloud or both or replicate between? Uh how do we reduce our costs if we were using managed databases in multiple locations? How do we get, how do we get more out of what we're doing with our databases performance?
06:00
Didn't go away. We still have to be really careful about our performance. But in most cases, now we're talking about things like how many I apps do I want. How many I ops am I currently using type thing? We don't have to get crazy with short stroking discs and things, modernization. Uh We're trying to modernize our applications
06:18
and the way we modernize our applications has a direct impact on the database layer which again, I'm going to show in a second and customer experience and by customer experience, I don't really mean your actual the customers of your business. Um But a lot of times the customer for database administrators is the developer that's using the database um to, to make their applications.
06:38
So we look a little closer at some of the challenges that DB A S are having now is this is a, is a modern app on the right on the right hand side here. Um There's lots of individual micro services and all of those micro services are no longer tethered to this single monolithic database anymore. Now, they've got multiple types of databases that they can use and each micro service um can
07:02
have its own type of database. So as opposed to having one application that was always talking to a A SQL relational database, now we might have one application that's got 10 micro services and each one of those is using uh like a no SQL database, a relational database. Um uh Cassandra Mongo DB. My sequel are examples that we've got in here.
07:24
Uh And, and things that aren't even databases like QS, sometimes database administrators are actually responsible for things like a Kafka Q, even though a Kafka Q isn't technically a database, right? But data goes through it. There's things about data pipelines that database administrators are now starting to work on.
07:41
Um And this has been um increased by the way we handle modern apps. So we're doing things like analytics, search A I and ML in some cases now it's a hot buzzword and streaming services. So I've listed the two databases we typically saw in the wild uh Microsoft sequel and Oracle Databases. But in relational databases, those have
08:02
exploded too in the last few years. Um As uh they, they became closer to feature parody with those database with the the big the big players. So my sequel is available now, all the cloud vendors have their own types of databases now for like Amazon Aurora or Google Bigquery, Amazon web shifts in here as well. But now we've got other categories of those databases.
08:24
So non relational databases, we might have red uh We might be doing cashing. We've got Mongo DB, couch base, couch DB elastic search, there's tons of these and each one of those may have a different flavor depending on which cloud you're running on or if you're running on prem. And then lastly, we've got other data sources. Apache.
08:42
Kafka Amazon SQS is a QE system kind of like Kafka Amazon Kinesis is another queuing system from Amazon. The point of this slide is there's a heck of a lot of databases out there at this point. The database administrators didn't used to have to manage. Now they do. So let's look at this microservices based application again and put it in a certain lens,
09:05
think about this application and how you would have to deploy this application in your environment. I don't know how long it would take you. My guess is if you're using older processes that are ticketed based, this is going to take a little while because for the application developers to start deploying the micro services, they're going to have to deploy Cassandra and console and Mongo
09:24
DB and mysql, all of those things take time and they're going to need somebody to look after them and make sure they get deployed correctly. Not only that we have to deploy all of these things. Not just once, but we probably have to deploy them for lab development qau A and production environments. Right?
09:40
I have heard in many cases where uh application teams will request a database from a uh a team or they'll request storage at least for, for a team and they're deploying their application, destroying it starting over all of these things multiple times. And what they would really like to be able to do is destroy the database and bring a new database back up with that application, but it just takes too long in uh an enterprise to get
10:06
all those things done. So what they typically do is they have their own routines to wipe a database clean after they've tested something. So they don't have to go through this ticketing process or anything again to get the database deployed, their process doesn't match up necessarily with the infrastructure or the platform team's processes.
10:24
So how do we ensure our applications are always available? Um In the same situation, imagine making sure that all of these databases are highly available and have disaster recovery processes for those and they've got data protection. So we know that they've been backed up correctly. Um All while trying to do this with self service, right?
10:42
If I need to deploy databases faster, I need self service. And I still have to have all these capabilities, I would need to be able to scale them up when performance is needed or scale them out, depending on what kind of database you're using. And I also would like to have a little bit of elasticity because sometimes the database is too big. We, we over provisioned it when we first
11:00
installed it, we were wrong. Let's scale it back down so we can save on some of our costs. And then of course, we have to secure them, imagine trying to take this one app and patch it. It would probably take a lot of time. We've got to do database upgrades on all of those things.
11:17
We've got role based access controls and encryption, all of those things, take database administrators time. Ok. So the point really is there's too many options. The old database administrators only had two things to worry about oracle or sequel. And typically they picked one for their environment. They weren't using both. Now, they've got all of these databases to
11:36
manage and they've got to do all of these things that are over here on the left side for those databases and on the right side, don't forget they've got all of those databases across multiple clouds. So they're, they're managing multiple, in some cases, multiple production environments, let alone just the DEV and Q A environments that they're also responsible for.
11:58
So to prove my point here, here's an application built on Aws hypothetical application. It's got three containers in the middle that are supposed to represent your micro services and then they're connected to their own databases. And on the top left, we've got Amazon R DS the bottom, right. We're also using Amazon R DS.
12:16
On the bottom left, we're using um Mongo DB or a document database from Amazon. And on the top right, it's an Amazon SQSQ. We could build the exact same application on Vsphere and we could use my sequel and Cassandra and Mango DB and Kafka. And basically these two applications are the same, the database flavor is slightly different, but they're all either relational databases or
12:42
cues or no SQL databases. But think about how you would have to manage these. If you're a database administrator, there's too many options. It's too complex. Complexity is really the thing that's killing uh database administrators at the moment.
12:55
So there's a new way to do this. What if we started managing these things through containers. So I'm going to take a step back for a few minutes and just talk about some of the advantages of using stale data in, in containers and kubernetes. So I'm sure you've all seen a slide similar to this one here um where it's a comparison of a
13:13
VM and containers and you, you're stripping out the operating system from the containers. So you don't have to, you don't have to provision an operating system every time you do a deploying container. I'm not gonna beat this to death. But the idea behind containers is that we can build it one time and we can run it anywhere. All we need to do is have AAA platform that will be able to run a container,
13:35
whether that's an AWS or on Prem or on our laptop or wherever that might be. We get efficient resource utilization now because we don't have to manage the operating system inside those containers. We don't have to patch those. Um This all leads to things like cost saving, right? We're using less disk space essentially because we don't have to deploy an operating system for
13:55
every one of our databases. And as we saw earlier, the number of databases we've seen has increased dramatically uh for security purposes, we can manage the security of a single image as opposed to managing security across multiple types of databases. Um because now we no longer have to pick different flavors depending on what environment
14:15
it might be in. They're C I CD compatible because they're, they're resource efficient, you're building them based off of desired state configurations. So all of this is easily script and they're horizontally scalable. Typical new databases now are um not necessarily scale up as much as they are scale out so we can add additional engines behind the databases so that they can do additional reads
14:39
or writes or whatever we need to do. Now, containers doesn't solve all of those problems. Containers themselves are a little bit difficult to manage if you're just managing containers, if you've ever run a vsphere environment or something like that. Imagine running virtual machines on individual ESX I hosts without V center.
15:00
You, you would, you'd you'd struggle, right? You would be able to do it, it would be functional, but it would be hard to manage at any sort of scale. You'd lose a lot of capabilities like V motion and H A and things like that. Kubernetes is basically doing the same thing for containers. So Kubernetes is gonna give us the operational efficiency because is a,
15:19
is an orchestrator. So all we have to do is provide desired state. Kubernetes can act as uh the orchestrator to make sure that containers are deployed on the right nodes. And if there's failure events that it can restart those, the way it's properly supposed to be done.
15:34
It provides high availability cooper also gives us service discovery so that we can actually do scaling for databases. If you scale up a database, you can't just uh power on another database. You have to actually provide an end point for users to access that database containers can spin up and spin down very quickly.
15:55
Um So we need a way that you can actually have a single end point. So your application can talk to while those containers spin up and spin down and its infrastructures code, we can store all of our, our Kubernetes manifests in a version control repository. We can manage them much more like uh an application would or an application team would in in like get for example,
16:15
and we can manage KTIS that way as opposed to having to manually click things around having accidents when we do our deployments and things. And Kubernetes actually provides a way around vendor lock in. Now, obviously, there are very specific types of Kubernetes clusters. You can get them from VM Ware with Zoo, you can get them from Red Hat with openshift.
16:34
You can get them from Amazon through Eks Azure. Everybody has their own kind of flavor of this. Um But they're all providing the base set of features for managing containers. So you can switch back and forth between providers and under most circumstances, your applications can still continue to run including your databases. So let's think about how we can standardize this.
16:58
Now, I've got four different clouds here. Aws Azure, Google and vsphere. And if I wanted to deploy databases on each one of those, I'd have to have four different ways of doing that. But if I put kubernetes on top of those, all of those things are now more manageable.
17:13
So now we're reducing that complexity that the database administrators are having by using Kubernetes as a single platform. So no matter what cloud, I'm on, uh our database should still be able to run. So infrastructure is code, we can do things like set in our YAML manifest, something like the number of replicas. I need two replicas because I need to make sure
17:33
my databases are highly available. When I do that, the Kubernetes scheduler will read this desired state and say, OK, I need two pods deployed pods being a container if I go in and then say, well, wait a minute. I I need to provide an end point for these things. This is done through service and the service
17:53
knows where those containers are running at any given time. If the state changes those containers, the service's job is responsible for updating um where they're at the back end end points while they continue to provide a DNS name or an IP address for you to access those databases from the outside. If I change my number of replicas to three, that's all I have to do to scale my database.
18:16
Kubernetes will actually deploy another container for us, right? If I have to manage high availability. And let's say I have node one that goes down. Kubernetes will recognize that that node has gone down. It will also recognize that I was supposed to have three replicas.
18:32
And now I don't, I only have two now. So it will make sure that that that container gets deployed in another node for us taking care of some of our high availability availability issues. And the last thing I want to talk about is a kubernetes operator. So a kubernetes operator is a codified site reliability engineer.
18:52
So think about a person that has to go and manage databases and deploy these things all the time. Uh A Kubera operator is a way for us to put that in code. So what we do is we've got an operator that gets deployed in your knas cluster and there's different types of operators. You can have them for my sequel or for red or whatever you want.
19:09
Basically, you put that in your Kubernetes cluster and then you provide us a desired state manifest for your database. In this case, I'm deploying uh an no DB cluster and I've given it a name called my cluster and I've got two instances listed. So when the operator sees this desired state deployed to kubernetes,
19:30
it'll make sure there's two databases deployed so we can build all of these things through the operator. The operator is typically provided by someone by someone with domain specific knowledge of that database. So whoever provided the operator knows exactly how operate, how these databases should be deployed, how they should replicate data and how they should
19:52
handle a failure, how they should handle an upgrade so that you don't have to know all of these steps, you just have to know how to operate the operator, right? So you just have to look through the documentation and say, OK, here's an operator. For me, this is all I got to deploy my Cobert manifest and it'll deploy that.
20:09
For me, there are some challenges introduced by Kubernetes. I don't want it to sound like Cotti solves all of our problems. It doesn't, we need a little bit of help and Bob is going to explain some of those. Thank you Eric. So hopefully at this point, you know, that is awesome and it can help you deploy data visas in a modern way.
20:29
Uh But as Eric said, right, we we want to make sure that uh we identify the challenges that communities introduces. It's not a perfect solution and talk about how ports and pr storage can help you fix some of those challenges or plug those gaps and help you run databases and production on communities. A database is in production using communities. OK?
20:50
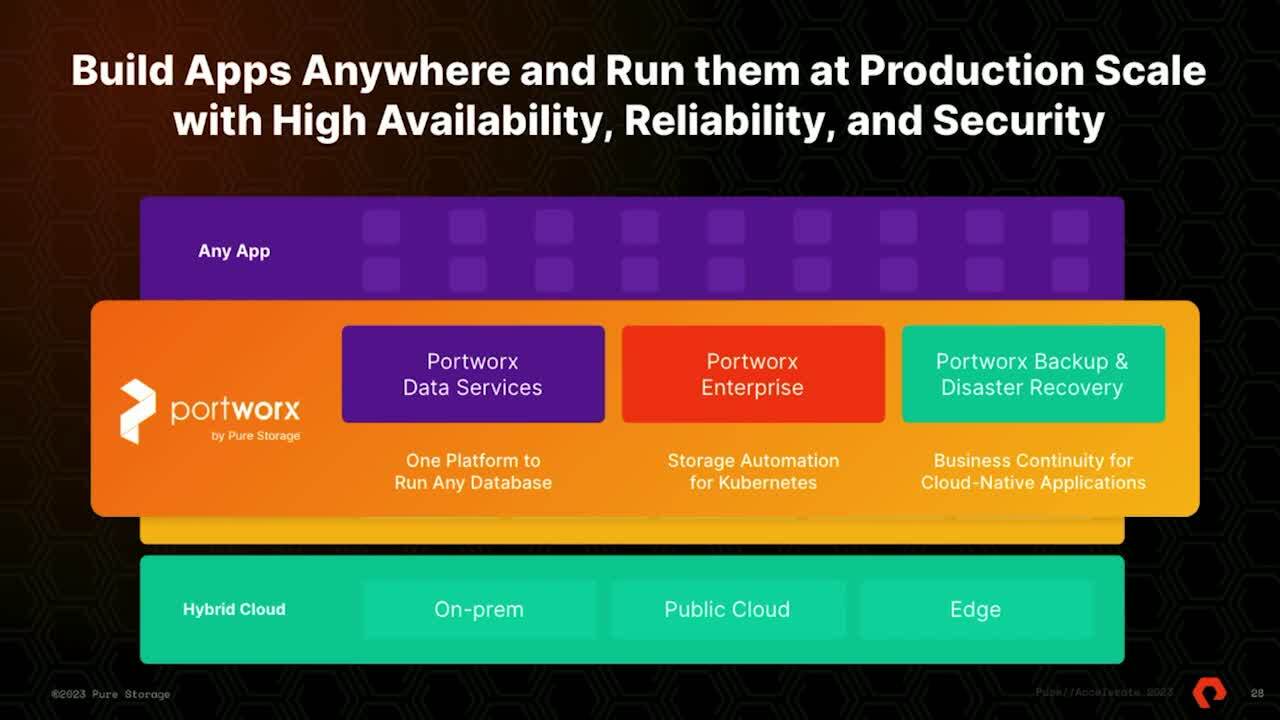
So before we talk about the challenges, let's talk about what port works is. So port works is the number one communities data platform in the market today. They have been recognized as the gold standard when it comes to community storage and data management by analysts for the last three years and works, the entire portfolio can run on any community distribution.
21:08
So you can run it on top of your Amazon Eks cluster, red open cluster, the VM and ZOO cluster. And we give you the same set of capabilities across any of these communities distributions because we run on top of communities as a cloud native or software defined storage solution, we can run anywhere communities can. So if you're running communities on bare metal Notes port works can run right on top of that
21:29
and consume storage from the physical devices or SSD or that you might have in that physical server or bare metal server, we can on virtual machines, we can run on public clouds and consume, let's say VM decay diss on a VM ware environment or consume EBS volumes in a public cloud environment. So uh port can run anywhere and then allow you to run any application on top. I think I heard one of my colleagues present
21:52
yesterday and they're like if you want to remember anything about port works, remember any, any, any, any community distribution, any infrastructure, any any applications on top of that? Uh The the portfolio of the platform is actually broken down into different services port works enterprise is that storage and data management layer that helps you run your state
22:09
full applications or your databases on top of communities uh works backup and disaster recovery, provide that data protection and disaster recovery capabilities that you need to run your databases in production. And then data services comes in with that single database platform as a service offering that allows you to run databases on communities in a simplified way,
22:29
we give you the day zero and data automation capabilities that are needed to simplify ongoing operations or deployment and ongoing operations for you. As that modern DB A, we want, we don't want you to spend time figuring out how to deploy these things on communities. We want you to spend time working with your application developers and figure out what their needs are and contribute to the top line
22:48
of the business. So we uh we have a few challenges that we wanted to discuss. Uh I know Eric mentioned that communities is that operating system for the cloud. It is that same consistent layer across different infrastructure stacks. But because of the way communities is built today uh And the plug-in based architecture that it has,
23:06
it leads to certain inconsistencies when it comes to the storage layer because any storage vendor can plug into communities using AC SI driver. That means uh if you are using a different storage solution on prem, you might have a different set of functionality and features. If you're running different uh if you're using uh uh if you're running things in Google cloud
23:24
or Azure, you have access to a different set of capabilities. Obviously, this is not uh sorry. Was there a question? Go ahead. Yeah, one, no. So port data service is a hosted control plan solution where if we host the control plan for you, the only thing you need to do is copy a
23:51
simple he command and run it against your communities cluster. It deploys a P DS agent and it connects back to the control plan so you can continue using port enterprise on top of communities. What you get with P DS is that U I or ASAP I uh set where we we have 12 different databases in our catalog today, including things like Mango DB Enterprise Microsoft sequel server,
24:11
Cassandra. And you can deploy these on your existing communities cluster without having to figure out what operator to use or what deployment uh what your parts should look like. It deploys everything consistently. And since it's a catalog that's curated by port works or by pr storage, we test these images not just for any issues but also for any CV or
24:31
vulnerabilities that come out. So we may we run security scans against these images. Whenever there is a CV that's identified in one of our images, we push a new image out and you can see that as a notification in the control plane, go ahead and update that version that's running on your communities cluster. So it gives you that ease of use experience when it comes to uh the running databases on
24:52
communities. We have a demo at the end of the session. If we have time for it, then we'll go through that. And I know Eric likes to use the word easy, like the easy things for you. No. So uh the lack of consistency, right? Going back to that point because you have inconsistencies across different infrastructure
25:08
stacks, you need a solution like port works that brings that level of consistency from a storage perspective. So port works is that cloud need a storage layer. It removes the dependency on the underlying infrastructure and gives you a consistent set of features. So if you need higher availability and replication, if you need encryption address,
25:23
you get all of those capabilities, regardless of where you're running port works or where you're running communities, you get that from the software defined storage layer. Talking about high availability. I know Eric mentioned that spins up the number of parts you need for your database using desired state configuration. So it matches the desired current state with the desired state.
25:42
And if one of the pod goes down, it spins up a new one and make sure that your current state matches the desired state. But it doesn't do that for a storage perspective, right? Like uh your persistent volume will actually take a few minutes to mount to a new location. And uh if it if if it's across or across regions, you won't have access to that data.
26:01
And if you are, let's say if your Cassandra node went down and eventually it came online back, back online. A new persistent volume was created for it. It will result in copying a lot of terabytes worth of data between different nodes in the CASA cluster, which is not actual application. It's just the new node trying to catch up.
26:17
This is where having a solution like port works, which has native replication built into the storage layer can help you where you can have your primary copy of your volume or your database on a single node with a volume attached to it. If that goes down, you have a replica that's running in the cluster because of the way port works works with communities and makes an orchestration or scheduling decisions.
26:37
We ensure that the new part is deployed on a node where the replica of that volume already exists. So it helps you with high availability from a storage perspective as well. Talking about encryption again, if you look at communities uh and encryption, the only thing that communities encrypts is your are your secret subjects,
26:54
which is where you store your user credentials. Obviously, that's a good thing, but it doesn't do anything for your persistent volume or your actual database contents. You need your storage solution to do that for you or you need your database layer to encrypt your data before it pushes things to the to to the disk. So this is where having a solution like code works can help you,
27:14
it can allow you to configure encryption at the cluster level. So any volume that gets deployed is encrypted address. By default, you can have a single key for the entire cluster. Uh or you can use individual private keys for encrypting individual persistent volumes for different instances of the database that you might be running.
27:32
So that's fully supported with code works as well. Talking about deployment architectures, I know operators is the way to go to deploy things on top of communities. But there are still people who are deploying things using a chart or using actual YAML files. And when you're doing that, you, you might end up in a situation where different users inside your organization might
27:52
use different ways to deploy applications or databases on communities. Operators are smart enough to figure out how they want to consume storage charts still need. Uh Still don't have that information. If you're just using YAML files, they still don't have that information. So there are different deployment architectures that are supported by communities, but it leads to confusion leads to an inconsistent
28:12
experience. That's where having something like port works deployed at uh across all your communities. First, make sure that whenever you deploy something, there's always a default port works class available that gives you all of the same functionality everywhere. In addition to this in the works data services, since we brought it up. Uh port works has its own operators for all the
28:30
different 12 different data services or databases that we support. So in instead of you having to figure out which is the correct operator for your in uh uh use case, you can just rely on port works and we give you a consistent experience across those operators as well. Talking about inefficient resource allocations as the next challenge doesn't force you to enforce resource requests and limits.
28:52
What do I mean by this? It doesn't uh ask the developers to enforce or specify what are the minimum resources and maximum resources. Uh a specific application compound or a database port needs. Uh It doesn't do that from a storage perspective as well. Uh This is where ports can come in and help you. Uh If you're just talking about the storage
29:11
layer, it helps you set maximums when it comes to IOP, read and write IOP from a storage perspective, read and write bandwidth when it comes to storage. It also allows you with solutions like works data services to have templates in place. So that if your developer is deploying something on a self service basis, using the user interface,
29:27
they have to select something from the drop down. So any database that gets deployed has those limits in place. So you don't have a noisy neighbor issue and then talking about anti affinity as that next challenge uh communities when it schedules these parts it just looks for available resources. It doesn't enforce any sort of uh anti affinity
29:45
rules when it comes to deployment. Uh If you look at the diagram that Eric had earlier, you had four nodes. But if communities decided to schedule all three replicas on that single node, you might be in a situation that if that worker node is the one that's supposed to fail or is failed, you, you might lose all three replicas of your database. Not a situation we want to be in.
30:05
You want a solution that can help you enforce anti affinity rules. So your part database parts or database replicas are actually spread across your Cassandra nodes are spread across your brokers are spread across your communities cluster and then backups. Uh you know that database clustering is just one thing, but you still want to take backups of everything that's running responsible for
30:26
running your database on communities. This means you have to protect your persistent volumes because snapshots are not enough. But you also want to protect all the secrets, all the deployment objects, all the service objects, everything that is needed to run a database on communities. You want to make sure that you are protecting all all of those resources and storing it in an S3 bucket.
30:44
This is where a solution like port works backup can help you protect your applications and you can store these application backups in any S3 compatible repository or even an NFS. Repository on the back end and finally disaster recovery. I have one more challenge after this. Uh But talking about disaster recovery communities doesn't give you any sort of disaster recovery capabilities.
31:06
And if you, if you talk to any organization that's running things in production, they won't do that without having AD R plan. If you are even you, when you're doing virtualization, you need something like a me a stretch metro metro cluster. uh or you need something like a VM Ware Srm to help you build Dr solutions for any applications that you're running doesn't have
31:26
that capability built in. This is where vendors like port works can help you. And we are the only vendor that can provide you disaster recovery capabilities for your applications on communities across different communities, distributions across different clusters. So you can create a synchronous disaster recovery solution with an RPO of zero or a a
31:44
zero data loss scenario where if your primary cluster goes down, you can bring your applications back online on the secondary site in a matter of minutes and, and continue solving user traffic. Or if you wanted to establish a cross region architecture right where you are. Uh maybe let's, let's say you're going from an AWS to a GKE cluster as a primary secondary combination,
32:03
you can't meet the 10 millisecond latency requirement for synchronous. Dr you need an AYN DR solution, there's a 15 minute RPO, but you can still have that Dr solution. So if anything happens to AWS, you can recover your applications through GK giving you that uh insurance or to make sure that your applications are back up and running migration again.
32:21
I know Eric spoke about how is that consistent layer everywhere but it doesn't help you migrate things. It, it just you can deploy it once and then you can deploy it again and you can deploy it the third time. But it's not about moving your applications that already has data associated with it. It's no longer, it's it's not efficient or it's not enough to just deploy those YAML files over
32:42
and over again. You also need to move the data along with it. So having a solution like port works allows you to perform one time migrations. Let's say you decided to start with the community's journey on the Red Heart open shift. But tomorrow you got a directive from your management team that you have to move to the public cloud. You want to move to Amazon Eks.
33:01
How do you do that? How do you take your existing applications and move to Amazon Eks having a solution like port works can allow you to perform these one time migrations. It can go from on prem to the public cloud or if you want to bring applications back, you can do that with port works as well. So those are all the challenges and with hopefully solutions that made sense.
33:19
Uh when it comes to running databases and communities. We do have a couple of demos for you. Uh I'll do one, I'll hand it off to uh Eric to do the second one. But in this demo, what we are doing is we are using an open source operator for Cassandra uh called the CAS operator. Again, you can find it on operator hub dot IO
33:37
and we are using that and using enterprise at the storage layer. So that when you're deploying your Cassandra cluster, you get capabilities like high availability volume, affinity snapshot schedules from the storage layer itself. So one the first step in in this demo is deploying the actual operator itself. So we are deploying the data stacks operator for a from uh for Apache Cassandra.
33:57
And then once the operator is up and running, it's in that succeeded stage, we'll go ahead and look at the port work storage class. So the port work storage class allows you to configure a few things. It allows you to configure the replication factor. So how many replicas of that persistent volume need to exist on my community cluster?
34:12
What are the resource limits when it comes to read IOP S and write IOP? Do I need to enforce volume placement strategies and anti affinity rules using volume groups? And then as an admin, I would rather uh define my snapshot policies and snapshot schedules in a in my storage class itself. So I don't have to go and modify my thousands of persistent volumes that I might be using.
34:33
So I can define these things inside the storage class object itself. So whenever a volume gets dynamically provision, using the storage class, it it inherits all of these schedules and enforces and enforces these snapshot uh schedules as well. Next step is creating a YAML file for my actual Cassandra cluster.
34:52
So here, as you can see, we are deploying a Cassandra data center called DC one, we have three racks defined in it. We are specifying requests the minimum resources I need from AC P and memory perspective. But I'm asking this Cassandra instance to use the cash dash PXSC as the port storage class. So all the features, all the parameters that we saw in our storage class gets implemented and
35:13
it gives you my Sandra nodes a 10 gig persistent volume at the end of the day. So once we apply this Cassandra cash dash Cassandra dot ML file in a specific community's name space, we can see that it automatically talks to my storage class, deploys my persistent volumes and mounts it to those Cassandra pods or Cassandra nodes. Uh Our our persistent volumes are up and running are in the bound state.
35:36
And as you can see the operator, right, instead of me having to deploy all of these things individually or manually, I just told the operator to deploy a three node Cassandra cluster for me and the operator is deploying a state, full set object for each node or each rack, it is deploying a pod for each of these racks and then it's also deploying all the different service objects. So instead of the user having to do this use uh
35:57
an operator which is as Eric said codified SRE or a software based SRE that can automate all of these things. Uh Once this is done, you can actually navigate to or exec into one of those portal spots to look at the the persistent volume that's being used by your Cassander node. So as you can see, we have three persistent volumes that were provision for those three
36:16
nodes. Let's inspect one of those volumes, right? So the things that we configured in the storage class are now reflected here. So it has a max max IOP of 10 24. It has two replicas configured across two worker nodes inside my same communities cluster. And I have data locality enforced by uh by having the port run on the same node.
36:35
If that node goes down, if the 55-56 node goes down port works will work with communities and spin it up on a different note that already has a volume replica. We we can also see the snapshot schedules that you might have. So again, the developer, the administrator only had to do this once the developer never has to worry about high availability, never has to worry about snapshots.
36:55
All of that is taken care by this port work player. The point that we want to drive here is you get the same functionality regardless of where you are running bare metal virtual machines in the cloud because port work is that software defined storage la with that, I'll hand it back to Eric to talk about portals, data services and show you how easy it is.
37:13
Thanks Bovin. So the last one we're going to talk about is port works data services. This is the third product in our portfolio. Um Currently, we have 12 data services that you can choose from. And as Bovin had said earlier, these are curated by port works. So anytime there are updates to these uh the the versions of say my sequel,
37:32
uh we'll have a new version of our uh deployment shortly thereafter. So we make sure that we're covering all your CV ES and things as well. All you have to do is make sure you're deploying them correctly. So here's the gooey of our deployment system. You would connect this to one of your knas clusters. And that's done by basically deploying a helm
37:50
chart and we show you how to go, you can go into the settings of the configuration here and set up your clusters ahead of time and you can, you can define what clusters you're going to do. You can do these deployments on it doesn't matter where those clusters live, you can do some on Amazon, you can do some on Prem, you can do both, right? As soon as you've got them connected,
38:07
you can start deploying your data services. So in this case, we're going to pick one of these data services and I'm not sure I remember which one we're doing. I think it's my sequel, Postgres. That's the one I meant to say. And then once you set that up, all you got to do is answer some questions.
38:21
So I get to pick what version of Postgres. I'm actually going to do. I'm gonna give it a name. So I've got something descriptive in a later on to, to tell me what this database is. I'm gonna pick which I'm deploying it to. Then I get to pick which cnet's name space it gets deployed to.
38:37
And then next, this last setting here is um a option to provisional load balancer. So K uses that term service, right? That's the thing that keeps track of all the pods that are running in your knas cluster. Uh You can also have those services be external services as a load balancer. So like if I deploy on AWS, if I choose to deploy a service of type load balancer,
38:59
it actually deploys an Amazon uh A LB and connects it to your Kubernetes cluster. So your applications outside the knas cluster can reach into the kna cluster and access these databases if you want it's up to you. Um Then we have an application configuration, we have different templates on the way our databases can be deployed. So you might have specific features of like my
39:20
post grass here that you wanted to turn on or turn off. We get to pick the number of nodes. In this case, I look to be deploying only a single node. So it's not highly available. But what we are doing is choosing a replication factor here of two in our storage options if that will go away.
39:40
Um So a replication factor of two is one way for us to make sure that whenever we deploy this database, the bits are going to be written to at least two nodes in your cober cluster. So if you lose a single node, we all, we have all of those bits already so that the database can be restarted on the other node that has the data already on it. So we only have one database here, but we have two copies of the data.
40:03
So this is an important thing you'd have to think about when you're deploying your applications. If your databases themselves are going to be doing the replication between each other, you might not want a replication factor of two, you might want a replication factor of one because the databases themselves are making the copies of the data. If that makes sense.
40:19
In this case, I'm only deploying a single node. So we have a replication factor of two set up here. And then lastly, we get to set up our backups at the bottom here so I can set up a, you know, an hourly backup. And I get to choose my target which is an S3 uh bucket in AWS. At this point. The deployment comes up here and you'll see a
40:37
bunch of, you'll see some errors or like some warnings that are happening here. These are events that are happening in your Cubers cluster related to this deployment. When it finally gets done, deploying, this should go green and those events will go away. They're not important anymore. And you can look at the connection details and you'll see the end points.
40:54
This is a DNS name to access those databases and a set of credentials. We can also take ad hoc backups any time we want to once it's been deployed. And then you can see the backups down here at the bottom. So you can uh do a restore in the future. Also, now that I've got my deployment done, in this case,
41:13
I'm scaling my deployment. So now I want two nodes, all I had to do is go in and change the number of nodes to two kubernetes is now going to go and deploy our second node and set up a synchronous replica between the two nodes. So that I'm actually replicating data between the two postgres databases. And I've also got a replication factor of two. So in this instance I actually have four copies
41:36
of my data because I have two for one node, two, for another node and they're replicating between each other, right? So that's four. Um I can also update Post so that we can scale it out either up or down. Uh In this case, I'm actually doing an upgrade. So I picked an older version of post wanted to do an upgrade and it's going to do those in a uh a staggered pattern so that we do one at a
42:02
time and you don't lose your data and then we can see some information about the database itself. So we're going to see the amount of IO that's actually being used by those databases. So you get a little bit of performance monitoring in here as well. There's not a good graph here to actually show you what's happening in the databases because
42:17
there's not really anything going on in those data. They were kind of just empty for this demo. Um But that's uh data services. We use an operator under the under the covers right there for that, for that to work. But we've kind of made it a little easier to
42:31
use with this gooey and giving you the options. So you don't have to like fiddle through YAML manifests all the time. So in summary containers and Kubernetes can reduce the overall complexity of your hybrid cloud environment. Database administrators have too many things to manage now, it's too complex. Kubernetes can make it easier as much as
42:49
Kubernetes itself sounds complex. It's actually here to make your lives easier. Port works, gets to do the same thing for your state full workloads. So what the pieces that Kubernetes can't fill in port works does for your state? Full applications. We give consistent storage operations regardless of what environment you're in. We don't care if you're on Aws or on Prem.
43:10
We give high availability of your staple workloads across fault domains like availability zones. Amazon specifically elastic block storage is only available in one zone at a time. So if you lose an entire zone, you don't have a way for your data to be restored unless you've taken back ups or your EBS volumes. And that's a lengthy process to do a restore.
43:30
And another availability zone port works can do that for you. We do the encryption of your storage volumes. Kubera doesn't do anything about that. We will efficient resource allocation through reservations limits and auto scaling of thin provision, volumes, provision. Amazon EBS volume at 50 gigs. You're paying for 50 gigs. If you use port works volumes,
43:53
you're using thin provision volumes and you can scale as you need to. We provide disaster recovery with zero RPO for those metro dr environments that are less than 10 milliseconds of latency and we do portability through backups or migrations. Um We also do things like backup sharing. So if you have uh your developers that are looking to do uh some testing on production data.
44:18
You can actually share a backup, not a backup job but a specific backup with your developers so that they, they can restore those on their own in Cober netti the way they want to. So you don't have to give them too many permissions in your backup software for them to actually go and get self service access to data, for them to do testing against. Um, last, but not least that's the end of our session.
44:41
We have one more session today. It's in this room. It's right after this and it's our port works, food services, engineering expedition. We did this session yesterday. It went over really well. If you weren't here, I recommend checking it out today.
44:54
Thank you. You would see if we improved the second time we do it. Yes. Yeah. If you want more information, you can scan this QR code, uh or stop by the booth. We'll be at the booth until five o'clock, six o'clock, 5 to 65 to 6. We'll be in the booth until it's over,
45:11
uh, and come by and stop and talk to us. Thank you very much. Thank you.