00:10
Andrew Nelson: All right, thanks, everybody for joining. My name is Andrew Nelson, and I am your Pure Storage hosts for this session. You are now attending cloud native Kafka with confluent and Pure Storage. I am a field Solutions Architect on the flash blade team at Pure Storage. And that means mainly
00:34
focused on analytics and software development or dev road practices around our flash blade product team. And I'll let Mark introduce himself and confluent. Marc Selwan: Thanks, Andy. Hey, folks, my name is Mark sell on product, working at product at Confluence, specifically
00:53
focusing on Kafka storage and data balancing. happy to chat about some cloudhealth Kafka and Pure Storage. Cool. So as some folks may or may not know, confluent, we provide an enterprise distribution of Apache Kafka, we also have a event streaming platform as a service in our cloud, obviously,
01:17
we're going to be focusing today specifically on the confluent platform side. But there's some important stuff happening happening in the last year actually. And you can you can go to the next slide, where a lot of the work that we have been doing in cloud to solve problems like operational problems,
01:37
scaling challenges, things like that, we've actually been releasing them as features for our self manage users on the confluent platform side. So today, we're going to be specifically focusing on that box that says performance and elasticity. So our self balancing clusters feature our
01:55
tiered storage feature, and how we work with Pure Storage flash blade to bring a more cloud native experience to our self manage users. So let's go ahead and talk about tiered storage. And this is this is a pretty interesting paradigm shift for Apache Kafka. And next slide, Andy.
02:19
Andrew Nelson: Yeah, and, you know, really, Kafka stands out as a product unto itself. But it came from a lot of the humble beginnings of Hadoop, where being able to do this type of, you know, messaging and open source product on regular x86 hardware had a ton of potential. And in small use cases, super
02:45
easy. All you need is a couple servers or a couple VMs, or instances. And now you have an event streaming platform to leverage. Now the difficulty with this, just either in bare metal or, you know, kind of Singleton scenarios, is the the two problems we're looking at, is simplifying the amount of
03:09
storage because of course, everything getting passed through this, the storage queues are persisted to storage disk. And you know, what the performance that you maintain, is essential to the platform. Because this is a real time streaming platform, you want to make sure that as you scale up
03:34
or out a Kafka cluster, that you're not held back by either of those two management components. Marc Selwan: Exactly. So this is where the whole idea tiered storage comes from. Now, when you think of tiered storage, in the traditional database world, you think about it as your hot
03:52
data store in your cold data store. But truth be told, these days, object storage is getting so good, so fast, and unmatched reliability that really ends up becoming like hot data, and maybe slightly less hot data. But even then, and just take a step back tiered storage is the idea that we continuously
04:18
archive data to efficient object storage. And so this has a lot of interesting implications, right. So this is a way of decoupling storage from compute effectively, because we think about it, you can keep a small subset of data local to the broker, and then most of your data resides in this super fast
04:40
and efficient object store. In our case, we're talking about flash played here. So that has cost of ownership implications because you don't have to worry about infrastructure sprawl as you scale individual components. And this helps tremendously with elasticity and making your self manage environments feel a
04:59
little bit More cloud native, and we'll talk more about that as we go along. Next slide. So just to summarize really quickly how it works at a high level, you have a traditional Kafka cluster, you've got your brokers, your brokers have local storage. And then the new piece here is the introduction of this
05:17
long term storage flash blade as an object store. And as I mentioned, the way it works is as data is being written, it's automatically being sent to object storage as it's being written. And so this local storage, you have a new parameter, we call the hotset, which is a unit either have
05:36
time, so how long you want to retain the data locally, at the broker layer, or how much data you want to retain there. So you can be as aggressive as you'd like with this or not. We have some users who, for example, maybe store seven days locally on the broker, and they'll store months two years of data in
05:54
object store. And so this is what begins to give you that flexibility or that elasticity. We'll talk a little bit more about that in a second here. Next slide. Andy, do you want to chat about this one? Andrew Nelson: Yeah, absolutely. So here, you know, in day two
06:09
operations, once you get your cluster up and running, you know, you'll have scenarios where it's so successful, you want to take on more topics, you want to take on more streaming data, you'll need to add servers for either compute or storage. And really, since these are coupled in that traditional
06:31
scenario, you need to add, you know, either way, you're going to need to add more servers to this cluster. When that happens. All of that data is potentially need to be rebalanced. And confluent, has its own feature for you know, balancing clusters. And otherwise, this is going to be you know, we're just
06:50
with regular Apache Kafka, that's going to have to be a manual process. But all of that data is then transferred over your network to make sure that all the nodes are up to date, and actually handling that additional load with flash blade. Now that we have the storage, separated, or
07:11
disaggregated, from the compute nodes, or at least that hotset that Mark was talking about. Now, we just need to slide new blades into that chassis, or we can expand additional up to 10, interconnected chassis use of the flash blade for a single flash blade instance. That way, we're adding more storage and
07:34
more storage throughput, complete on the back end that's already self contained, and not necessarily going over your network. The same point, if we need to add compute nodes, very simple, we can add nodes to add processing capability on the compute side that isn't tied to storage. So we're not dependent
07:54
on the number of disk chassis slots that are already in a compute node, we can focus on, you know, CPU and memory and that essential, you know, the most hot data that is most relevant to the brokers. Marc Selwan: Okay, so let's dive a little bit deeper into what's
08:12
happening at the topic level, because I think this is pretty important. It talks to some of the efficiencies that we've made that really helped play towards each of our strengths, right. So as you write data to a Kafka topic, these obviously get written to a log. And as these roles as these logs roll off,
08:32
they roll off into these segments. And it's these segments files, these are the things that are getting uploaded are archived to object storage. Now, as an efficiency mechanism, we only upload the segments from the partition leader specifically. So as you may now in Kafka, we have replication
08:50
factor to help with high availability. So very common tag replication factor of, let's say, three, for example, we don't want to send three copies of the data to the object store, because flashlight has its own availability and durability mechanics. And we want to let flash blade do what it does best
09:06
when it comes to the object store mechanics there. So we just send the partition leaders segment over to the object storage to help first of all reduce the amount of storage that is required on the object storage side. And it also helps from a read performance perspective, because we don't
09:22
have to reconcile the data. Every time we just ping object storage, we know exactly what we're looking for. And flash blade sends us exactly what we need. Next slide. And so we mentioned some new parameters, some new terminology, it's introduced in the Kafka world, mainly the hot set, right? And
09:41
the hot set is that thing that controls how much data or how long you want to keep data at that broker layer and configuring tiered storage. To work with flash weight, super simple. You just configure it as an s3 endpoint. The special bit there is that endpoint override. That's where you were Put your
10:00
flashlight endpoint. And it's also worth noting that you can configure tiered storage either either as a cluster wide default, so as you create topics, it'll automatically have tiered storage enabled and start tearing data immediately. Or you can do on a per topic basis, say if you have specific topics
10:17
where you want to have longer retention times than others. So lastly, just some other things to keep in mind, especially if you're interested in giving a try. As we mentioned, tier storage, you can enable it cluster wide or a per topic basis. I'm thinking about the hot site is also an important
10:36
thing, because it's, it's a business question, right? Like, how much do I want to keep on the broker side, which influences how you size your individual brokers. And there's also some technical considerations as well like, things like, okay, the more aggressive I set my heart set
10:55
to, I might have to have some more compute to be able to handle that load. It's also important to know that absolutely no changes need to happen at the client layer. To take advantage of this, all of the logic and magic happens at the broker. So your clients are still producing and consuming
11:12
just as they normally would note, no changes need to be happened there. And then as far as object store permissions are needed at pretty basic ones that you'd expect from a from an s3 compatible object store. And now we don't we don't need to, to set multi part upload, which is a common question that we get.
11:32
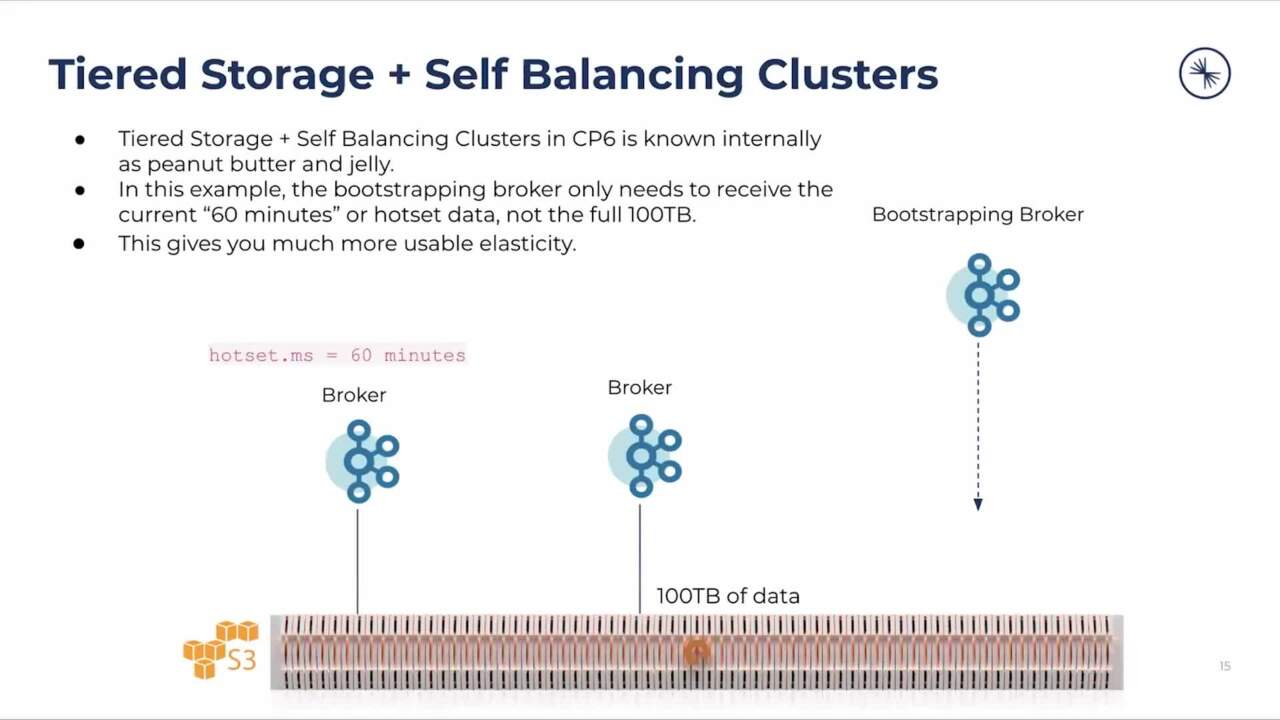
Cool. Next slide. Okay, this is where you getting some of the fun stuff, how it's used, like, where does the value and benefit of this come from? So internally, we call this the peanut butter and jelly use case, this is when you're combining tiered storage with our self bouncing clusters
11:49
feature, which is a new feature that we released alongside tiered storage, which automatically detects topology changes, whether you're adding or remove brokers, and does the partition distribution and reassignment for you in the background. So no longer do you have to do manual, partition
12:05
reassignment files, and manually run command line tools to do all this stuff. But the real magic here is if you think about it, right, if you got a hot set where you're storing a small amount of data locally to broker, let's say, 60 minutes, for example, that means when you're adding or removing
12:21
brokers, you only have to worry about streaming that 60 minutes worth of data. So that means that when you have an outage on a broker, or you want to expand or reduce capacity, it happens super quick. And this was a huge operational win for us. On the confluent. Cloud side, obviously, because no longer did
12:39
our engineers have to worry about doing any sort of manual work or an adventure when it came to having to optimize workloads or expanding or shrinking clusters. This is all happens automatically. And because of tip storage, it happens super fast. Next slide, Andy.
12:57
Andrew Nelson: Yeah, so let me talk about some more day to operations. Now, as we look at, you know, not just planned operations, if there's unplanned maintenance, of course, for a node or instance going down, then any of that data across those nodes needs to be reconstructed across the
13:19
surviving nodes. Of course, that's standard for Kafka. But all of that data, then that rebalancing needs to happen across the network. And that's additional load on nodes that are already busy and already under pressure whenever they're losing part of their storage throughput from a node failure.
13:40
And the disaggregated approach, of course, if there is any storage failure on the flash blade side, we're using n plus two a ratio coding to make sure that we have storage redundancy there. So any particular blade could fail and still not lose any of the aggregate storage throughput. At the same time,
14:02
all of the components are done of course, active active backplane you know, power supplies, fans, all of that. And all of that can be updated in place as well as non disruptively upgraded in the future, even if you wanted to swap out blades if you want a larger size storage, or all of
14:22
those pieces were made to be upgraded in place. Marc Selwan: Awesome. Another interesting thing that we're seeing, right is, well, there's sort of this evolution of how people are starting to use Apache Kafka, mainly around it being considered a persistent data store, if you will. And now
14:48
there's there's obviously some controversy around the topic of you know, is Kafka, a database replacement, is it not? But, but, I mean, the proof is in our users and a lot of users tiered storage are starting to use this as a way to efficiently store data for longer periods of time, especially for use cases where,
15:08
okay, well pay data is going to hit Kafka anyways. And it's connected to all of my downstream systems. So if I, the longer I keep data in Kafka, the easier it is for me to rehydrate downstream systems create materialized views in other databases or other systems for for my interactive queries, or
15:25
analytics or what have you. So it's been really awesome to see that this has really helped enable some of these some of these use cases that we've been talking about a conflict for such a long time. And this is like your dream becoming reality for us seeing our users start to use Kafka in this way. Next
15:46
slide. Any other fun stuff? Andrew Nelson: Yeah. And, you know, we, we talked about, you know, what were the the two issues were, you know, simplicity of management through those day to day operations. But now we get into the performance piece. And this is where flash
16:01
blade really needed to shine, if we're going to be able to maintain that historic performance with Kafka, if we're going to make that, you know, data available through not just the hot set of what's local to the servers, where we need to prove this out of what the array can actually do. And, of course,
16:22
you know, through our testing, we've been able to validate this against s3 on AWS, and saw, you know, three times faster reads on the flash blade, as well as comparing this to 2424 disk nodes, or disk chassis slots. And each node makes it a lot simpler to manage this in the flash blade form factor across
16:53
the number of instances in the Kafka cluster. And what we ran against this was several different streaming workloads so that we could do ingress and egress. So a very busy Kafka cluster. And at the same time, you know, we could be, you know, just, like Mark said, querying this data downstream. But if all
17:20
of the data is already part of Kafka, and it's easy and fast to be able to query that in place within Kafka, why not take advantage of that, and flash blade is that data hub platform that makes that possible, you know, simple and speedy across that architecture, so that even as the Kafka cluster needs are
17:47
increasing, or growing across additional topics or throughput, we can handle that additional load on the flash blade side, versus just a regular object store, which isn't necessarily optimized for that ease of use. Marc Selwan: Yeah, that's a that's an interesting point.
18:05
Andy, I do want to, I do want to pull on that thread a little bit, because there's a reason why flash Wade was our first and as of this time speaking, so far, only self managed support object store is it. So as I mentioned, a couple slides back, this idea of our users are naturally organically starting
18:30
to use Kafka as their system of record as a persistent data store. And that comes with a heck of a lot of responsibility, right. And so we think of tiered storage, and object storage as a first class storage medium for us. And it's really important for us to get that right. And so when we were working with the
18:52
flash blade team, and they're amazing lab, by the way, we had access to some pretty sweet hardware. It was critical for us to test obviously, like performance is key, right. And we had no doubts about the performance. In fact, I think some of these some of these charts are being a little bit
19:11
modest. I think at one point, we hit like over seven gigabytes per second, which is like, absolutely insane. But just as important as performance is correctness, durability, and availability. These are also things that are super critical, if not more important than the performance side of things. And
19:30
so we did tons of correctness tests, we did failure testing scenarios, things like that, to make sure that we could trust the object store as a first class storage medium. So and I think I mean, obviously, these charts are awesome to look at. And it was an awesome exercise, but I just want to make sure we
19:48
highlight the point that we spent a lot of time and effort, making sure that the storage layer is fast, and it's safe. And I think I think the numbers here speak for themselves. Anyways. Sorry, sorry, that's a good call out here. Andrew Nelson: Yeah, and, you know, finally, we talked too
20:08
much about that rebalance time, either, you know, planned or unplanned downtime. And this is the, you know, kind of the the hero graph. But, you know, when the cluster only needs to move its individual hot data, you can see here, the rebalancing the cluster, adding a new node, all of that is super simple. With
20:32
flash blade, instead of adding additional load to the cluster, adding additional storage, io requirements, all of this can be offloaded the flash blade so that you're just moving the essential data and let flash blade take care of the rest. And save a ton of time.
20:50
Marc Selwan: Yeah, I mean, there's, I mean, this is really what it comes down to, right. I mean, there's obviously awesome benefits and use cases that get unlocked by being able to store tons of data in that efficient object store layer. But really, like the big win here, really is around the operational aspects
21:07
of this. And, you know, it's not just a time thing, right? I can type thing is awesome, it's great that we can scale elastically really quickly. But think about it from an operational perspective, like this combined with that self balancing clusters thing I talked about earlier, you're
21:22
saving a lot of time and manual effort and manual scripting, scaling or recovering from failure. So like this is, I think it's a huge win for for operators on the Kafka side and not something to take lightly here. Andrew Nelson: Now, just to quickly wrap up, and we know
21:41
confluent, and flash blade are an awesome combination. Again, just, you know, I love my peanut butter and jelly sandwiches with a lot of peanut butter and jelly, my wife freaks out every time because she doesn't know, you know, it's just destroying my mouth. But you know, I love that, you know, confluent has
22:03
their self balancing clusters, the amount or the capability of tier storage, to be able to extend out their data set and query that data in place. Leveraging, you know, really what we focused on from the flash blade side, that we can simplify day to operations, simplify scaling out the storage
22:27
components, and, you know, hopefully the compute side as well as a Kafka cluster. And keeping that throughput where it needs to be, whether we are building out with, you know, a single flash blade system or extending that all onto multiple chasse ease, we can do that and maintain the speed and
22:48
reliability of all of that data for your Kafka cluster. Marc Selwan: Well said. Andrew Nelson: So, I invite you to check out the there's a couple blogs about this that we've collaborated with with confluent as well as our, you know, user case studies and our
23:09
Best Practices Guide. With that. Thanks for tuning in. And definitely let us know if you have any questions.