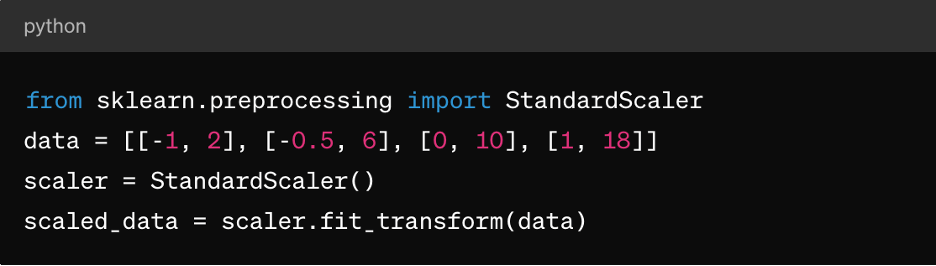
應用標準化指南
最小-最大擴展:最低-最高縮放適用於要求輸入功能在特定範圍內的演算法,例如神經網路和支援向量機器。確保異常值得到適當處理,因為它們會影響擴展。
Z 分數標準化:這適用於 k 平均群集、線性迴歸和羅吉斯迴歸等演算法。它導致以 0 為中心的分佈,標準差為 1,因此非常適合假設常態分佈資料的演算法。
稀疏資料:對於稀疏的資料集(其中大多數值為零),請考慮使用 MaxAbsScaler 或 RobustScaler 等技術進行標準化。
類別資料:對於類別功能,在正常化之前,請考慮使用單熱編碼等技術,以確保有意義的擴展。
值得注意的是,標準化技術的選擇取決於您資料的特定特性,以及您計畫使用的機器學習演算法需求。實驗和理解對模型效能的影響是有效應用標準化的關鍵。
3. 功能擴展
功能擴充是一種資料預先處理技術,用於標準化資料組的獨立變數或功能範圍。功能擴展的目標是將所有功能都達到類似的規模或範圍,以避免在模型訓練或分析期間,有一個功能比其他功能更佔優勢。功能擴充可改善最佳化演算法的融合速度,並防止某些功能對模型造成不當影響。
功能擴展在資料預處理中扮演的角色
擴展功能可確保ML演算法平等地處理所有功能,防止對更大規模的功能產生偏見。它還增強了融合,因為許多優化演算法(例如,梯度下降)在功能擴展時融合得更快,從而加快模型訓練。它還可以防止由於功能量級的巨大差異而產生的數字不穩定問題。最後,擴展可以更輕鬆地解讀功能對模型預測的影響。
功能擴展方法
除了上述最低-最高比例和 Z 分數標準化之外,還有:
MaxAbsScaler:這會依最大絕對值來調整每個功能,因此產生的值範圍介於 -1 到 1 之間。它適用於保留零條目很重要的稀疏資料,例如文字分類或推薦系統。
穩健的規模:這使用對離群值強健的統計資料,例如中位數和四分位距 (IQR),來擴展特徵。它適用於包含離群值或偏斜分佈的資料集。
應用功能擴展指南
若要套用功能擴展:
- 當資料遵循常態分佈,或使用線性迴歸、羅吉斯迴歸或 k 平均值叢集等演算法時,應用標準化(Z 分數標準化)。
- 當您需要資料位於特定範圍內時,例如神經網路或支援向量機器,請套用標準化(最小至最大縮放)。
- 處理稀疏資料時,請使用 MaxAbsScaler,例如文字資料或高維度稀疏功能。
- 在處理包含離群值或非常態分佈特徵的資料集時,請使用 RobustScaler。
請記住,在應用特徵擴展之前,類別特徵可能需要編碼(例如,單熱編碼),尤其是在標稱(未排序類別)的情況下。
4. 處理類別資料
類別變量代表群組或類別,通常為非數字性質,在模型訓練期間帶來挑戰,包括:
- 非數字表示:類別變數一般使用字串或標籤表示,大多數機器學習演算法無法直接處理。演算法需要數字輸入以進行訓練和預測。
- 一般變數 vs. 名義變數:類別變數可以是一般變數(有意義順序)或標稱變數(沒有特定順序)。將順序變數視為標稱變數或反之亦然,可能導致不正確的模型解讀或偏誤預測。
- 維度的詛咒:單熱編碼是處理類別資料的常見技術,可能導致資料集的維度增加,尤其是在大量獨特類別中。這會影響模型效能並增加運算複雜性。
類別變數編碼技術
類別變數的編碼技術包括:
標籤編碼:標籤編碼會為類別變數中的每個類別指派唯一的數字標籤。它適用於類別之間有意義順序的順序變數。
以下是使用 Python scikit-learn 的範例:
從 sklearn.preprocessing 匯入 LabelEncode
le = LabelEncoder()
encoded_labels = le.fit_transform(['cat', 'dog', 'rabbit', 'dog'])
單熱編碼:單熱編碼會為類別變數中的每個類別建立二進位欄,其中每一欄表示該類別的存在與否。它適用於在類別中沒有特定順序的標稱變數。
以下是使用熊貓的範例:
將 pandas 匯入為 pd
df = pd.DataFrame({'category': ['A', 'B', 'C', 'A']})
one_hot_encoded = pd.get_dummies(df【'category'】, prefix='category')
虛擬編碼:虛擬編碼與單熱編碼類似,但會捨棄其中一個二元式資料行,以避免線性模型中的多共存問題。它常用於迴歸模型中,其中一個類別作為參考類別。
以下是使用熊貓的範例:
dummy_encoded = pd.get_dummies(df['category'], prefix='category', drop_first=True)
類別資料的處理準則
為了正確處理類別資料,您應該:
了解變數類型:判斷類別變數是一般的還是標稱的,以選擇適當的編碼技術。
避免誤判:使用標簽編碼進行標稱變數時要謹慎,因為這可能會在資料中引入非預期的常式。
處理高基數:對於具有大量獨特類別的類別變數,請考慮使用諸如頻率編碼、目標編碼或減維技術等技術,如 PCA。
除了處理缺失值和標準化數值資料之外,這一切都是額外的。
5. 處理不平衡的資料
處理不平衡資料是機器學習的常見挑戰,尤其是在分類任務中,一個類別(少數類別)的實例數量明顯低於其他類別(主要類別)。不平衡的資料會對模型訓練和評估產生深遠的影響,導致偏向多數類別的模型,對少數類別表現不佳。
以下是關於不平衡資料與處理技術的一些關鍵要點:
不平衡資料對模型效能的影響
對不平衡資料進行訓練的模型往往在多數類別中優先考慮準確性,同時忽略少數類別。這可能導致少數族群預測的表現不佳。此外,準確度等指標在不平衡的資料集中可能具有誤導性,因為高準確度可能是因為正確預測多數類別,同時忽略少數類別而產生。精準度、召回、F1-score和 ROC 曲線下面積 (AUC-ROC) 等評估指標對於不平衡資料集而言,比單獨使用準確度更為重要。
處理不平衡資料的技巧
處理不平衡資料的最常見技術是超取樣和低取樣。超採樣涉及增加少數族群的案例數量,以平衡其與多數族群的平衡。低取樣涉及減少多數類別中的實例數量,以平衡其與少數類別。您還可以透過結合超採樣和低採樣,採取混合方式。
還有課程權重,您可以在模型訓練期間調整課程權重,以懲罰少數族群的錯誤,而非多數族群的錯誤。這僅適用於支援類別權重的演算法,例如羅吉斯迴歸或支援向量機器。
處理不平衡資料的準則
若要處理不平衡的資料,您應該:
了解資料分配:分析資料集中的類別分佈,以確定不平衡的嚴重程度。
選擇適當的技術:根據您的資料集大小、不平衡比例和運算資源,選擇超採樣、低採樣或混合技術。
評估指標:使用適當的評估指標,如精準度、回收率、F1-score或 AUC-ROC 曲線,來評估兩個類別的模型效能。
交叉驗證:在交叉驗證資料集中應用技術,以避免資料洩漏,並取得可靠的模型效能預估。
結論
資料前置處理有助於確保 ML 模型接受高品質、正確格式化的資料訓練,進而直接影響模型的效能、準確度和廣義能力。資料前置處理解決了遺失值、異常值、類別變數和類別不平衡等問題,使模型能夠做出更明智準確的預測,從而在現實世界應用中做出更好的決策。
有了適當的資料前置處理,ML 從業人員可以發揮資料的全部潛力,並為跨領域的各種應用程式建立更準確、更可靠的預測模型。
然而,要真正在現實世界中做到這一點,您首先需要有彈性的資料儲存解決方案,如 Pure Storage 幫助您加速 AI 和機器學習,並提前推動您的企業 AI 計劃。