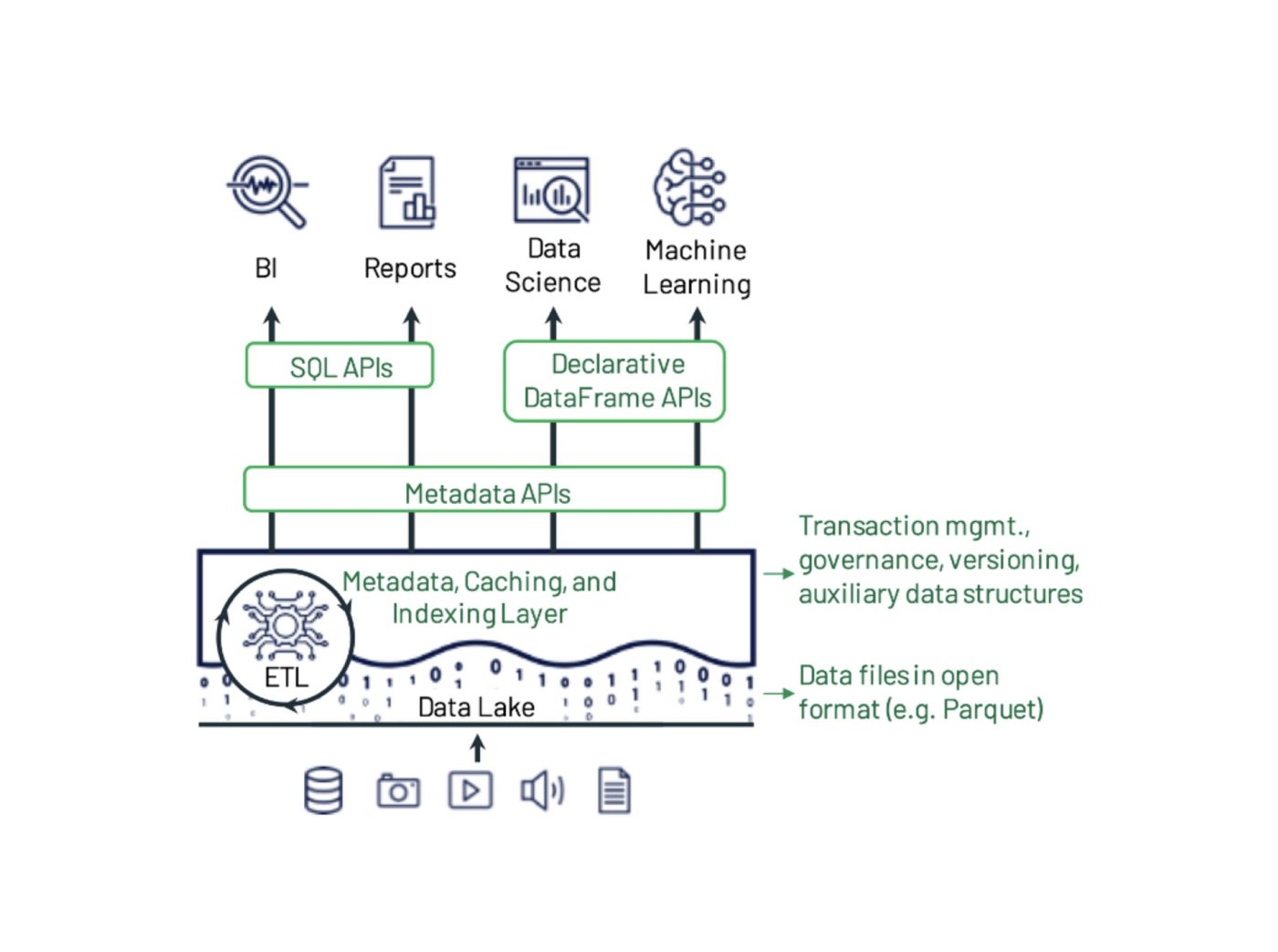
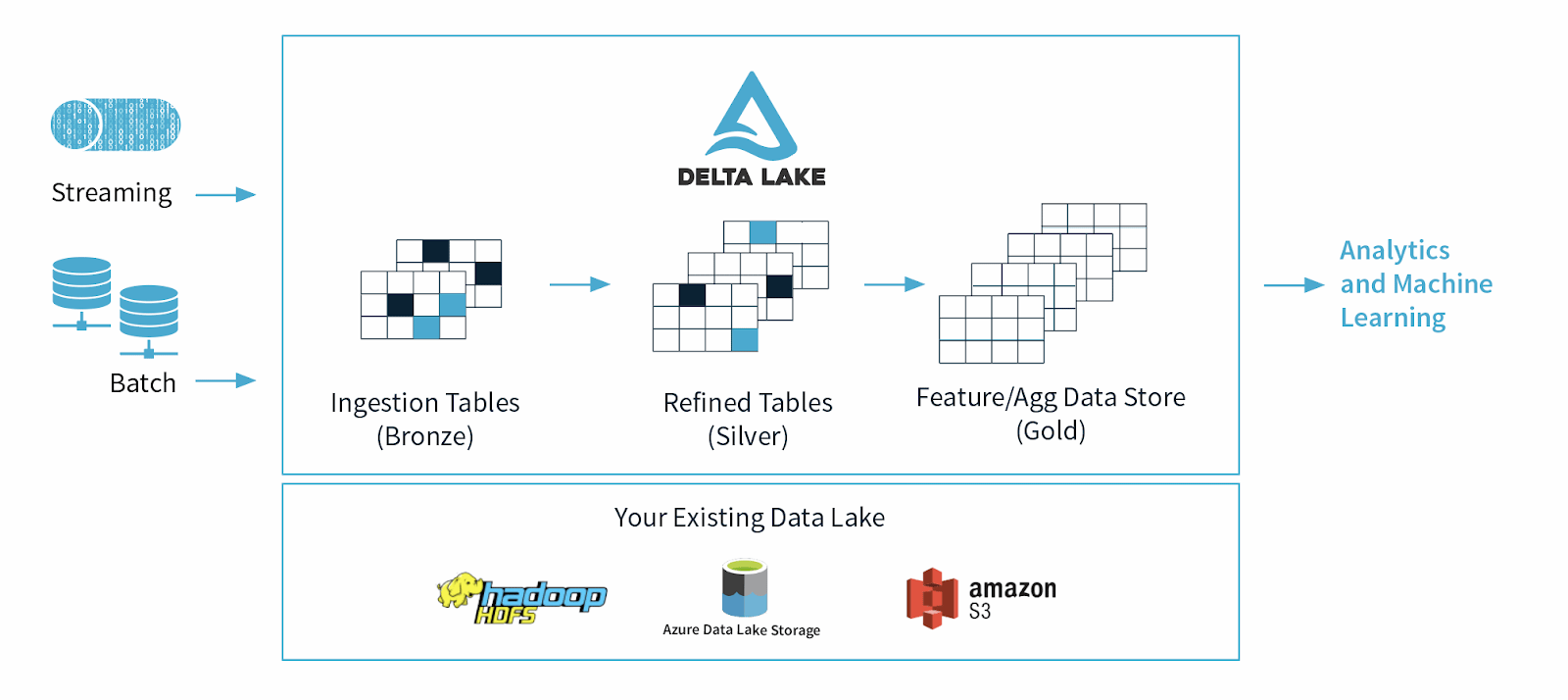
Delta Lake is een open source dataopslagframework dat is ontworpen om de betrouwbaarheid en prestaties van datalakes te optimaliseren. Het pakt enkele van de veelvoorkomende problemen aan waarmee datalakes worden geconfronteerd, zoals dataconsistentie, datakwaliteit en gebrek aan transactionaliteit. Het doel is om een oplossing voor dataopslag te bieden die schaalbare, big data-workloads kan verwerken in een datagedreven bedrijf.
Delta Lake Origins
Delta Lake werd in 2019 gelanceerd door Databricks, een Apache Spark-bedrijf, als een cloud table-formaat gebouwd op open standaarden en gedeeltelijk open source ter ondersteuning van de gevraagde functies van moderne dataplatforms, zoals ACID-garanties, gelijktijdige herschrijvers, datamutabiliteit en meer.
Wat is het doel of het belangrijkste gebruik van Delta Lake?
Delta Lake is gebouwd om het gebruik van datalakes te ondersteunen en te verbeteren, die enorme hoeveelheden zowel gestructureerde als ongestructureerde data bevatten.
Datawetenschappers en dataanalisten gebruiken datalakes om waardevolle inzichten uit deze enorme datasets te manipuleren en te extraheren. Hoewel datalakes een revolutie teweeg hebben gebracht in de manier waarop we data beheren, hebben ze ook een aantal beperkingen, waaronder datakwaliteit, dataconsistentie en, de primaire, een gebrek aan afgedwongen schema's, waardoor het moeilijk is om machine learning en complexe analytische activiteiten uit te voeren op ruwe data.
In 2021 voerden datawetenschappers uit zowel de academische wereld als de technologie aan dat, vanwege deze beperkingen, datalakes binnenkort zouden worden vervangen door "lakehouses", open platforms die datawarehousing en geavanceerde analyses verenigen.