Richtlijnen voor het toepassen van normalisatie
Min-max schalen: Min-max-scaling is geschikt voor algoritmen die invoerfuncties binnen een specifiek bereik vereisen, zoals neurale netwerken en ondersteunende vectormachines. Zorg ervoor dat uitschieters op de juiste manier worden behandeld, omdat ze de schaalvergroting kunnen beïnvloeden.
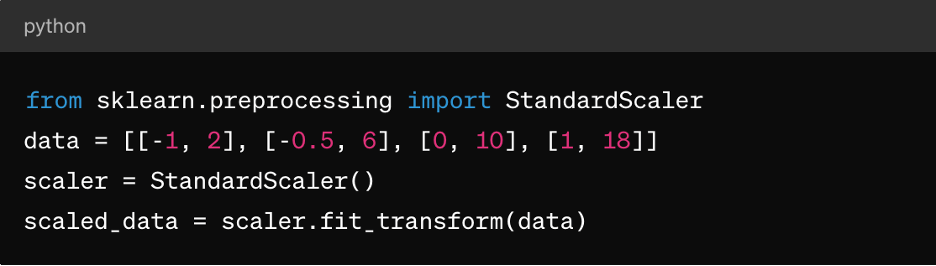
Z-score normalisatie : Dit is geschikt voor algoritmen zoals K-means clustering, lineaire regressie en logistieke regressie. Het resulteert in een distributie gecentreerd rond 0 met een standaarddeviatie van 1, waardoor het ideaal is voor algoritmen die uitgaan van normaal gedistribueerde data.
Beperkte data: Voor beperkte datasets (waar de meeste waarden nul zijn), overweeg het gebruik van technieken zoals MaxAbsScaler of RobustScaler voor normalisatie.
Categorische data: Overweeg voor categorische functies technieken zoals one-hot codering vóór normalisatie om zinvolle schaalbaarheid te garanderen.
Het is belangrijk op te merken dat de keuze van de normalisatietechniek afhankelijk is van de specifieke kenmerken van uw data en de vereisten van het machine learning-algoritme dat u van plan bent te gebruiken. Experimenteren en begrijpen van de impact op de prestaties van het model zijn belangrijke aspecten van het effectief toepassen van normalisatie.
3. Functieschalen
Functieschalen is een voorverwerkingstechniek voor data die wordt gebruikt om het bereik van onafhankelijke variabelen of functies van een dataset te standaardiseren. Het doel van functieschalen is om alle functies op een vergelijkbare schaal of bereik te brengen om te voorkomen dat één functie over anderen domineert tijdens modeltraining of -analyse. Functieschalen kan de convergentiesnelheid van optimalisatiealgoritmen verbeteren en voorkomen dat bepaalde functies een onnodige invloed op het model hebben.
Rol van functieschalen in data-voorverwerking
Schaalfuncties zorgen ervoor dat ML-algoritmen alle functies gelijk behandelen, waardoor vooroordelen ten opzichte van functies met grotere schalen worden voorkomen. Het verbetert ook de convergentie, omdat veel optimalisatiealgoritmen (bijv. gradiëntdaling) sneller samenkomen wanneer functies worden geschaald, wat leidt tot snellere modeltraining. Het kan ook numerieke instabiliteitsproblemen voorkomen die kunnen ontstaan als gevolg van grote verschillen in functieomvang. En tot slot kan schalen het gemakkelijker maken om de impact van functies op de voorspellingen van het model te interpreteren.
Functieschaalmethoden
Naast de hierboven beschreven min-max schaal en Z-score normalisatie is er ook:
MaxAbsScaler: Dit schaalt elke functie op basis van de maximale absolute waarde, zodat de resulterende waarden tussen -1 en 1 liggen. Het is geschikt voor beperkte data waarbij het behoud van nul vermeldingen belangrijk is, zoals in tekstclassificatie- of aanbevelingssystemen.
RobuusteScaler: Dit maakt gebruik van statistieken die robuust zijn voor uitschieters, zoals de mediaan en het interkwartielbereik (IQR), om functies te schalen. Het is geschikt voor datasets met uitschieters of scheve distributies.
Richtlijnen voor het toepassen van functieschalen
Om functieschalen toe te passen:
- Pas standaardisatie (Z-scorenormalisatie) toe wanneer de data een normale distributie volgen of wanneer algoritmen zoals lineaire regressie, logistieke regressie of K-means clustering worden gebruikt.
- Pas normalisatie (min-max scaling) toe wanneer u de data binnen een specifiek bereik wilt hebben, zoals neurale netwerken of ondersteunende vectormachines.
- Gebruik MaxAbsScaler bij het omgaan met beperkte data, zoals tekstdata of hoogdimensionale beperkte functies.
- Gebruik RobustScaler bij het omgaan met datasets die uitschieters of niet-normaal gedistribueerde functies bevatten.
Houd er rekening mee dat categorische functies mogelijk moeten worden gecodeerd (bijv. one-hot-codering) voordat functieschalen worden toegepast, vooral als ze nominaal zijn (niet-geordende categorieën).
4. Omgaan met categorische data
Categorische variabelen vertegenwoordigen groepen of categorieën en zijn vaak niet-numeriek van aard, waardoor uitdagingen ontstaan tijdens modeltraining, waaronder:
- Niet-numerieke representatie: Categorische variabelen worden doorgaans weergegeven met strings of labels, die de meeste machine learning-algoritmen niet direct kunnen verwerken. Algoritmes vereisen numerieke input voor training en voorspellingen.
- Ordinale vs. nominale variabelen: Categorische variabelen kunnen ordinaal (met een zinvolle volgorde) of nominaal (zonder een specifieke volgorde) zijn. Het behandelen van ordinale variabelen als nominaal of omgekeerd kan leiden tot onjuiste modelinterpretaties of bevooroordeelde voorspellingen.
- Vloek van dimensionaliteit: One-hot codering, een veelgebruikte techniek voor het omgaan met categorische data, kan leiden tot een toename van de dimensionaliteit van de dataset, vooral met een groot aantal unieke categorieën. Dit kan de prestaties van het model beïnvloeden en de complexiteit van de berekeningen vergroten.
Technieken voor het coderen van categorische variabelen
Technieken voor het coderen van categorische variabelen zijn onder meer:
Labelcodering: Labelcodering wijst een uniek numeriek label toe aan elke categorie in een categorische variabele. Het is geschikt voor ordinale variabelen waarbij er een zinvolle volgorde is tussen categorieën.
Hier is een voorbeeld van Python's scikit-learn:
van sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
gecodeerde_labels = le.fit_transform(['cat', 'hond', 'konijn', 'hond'])
One-hot codering: One-hot codering creëert binaire kolommen voor elke categorie in een categorische variabele, waarbij elke kolom de aan- of afwezigheid van die categorie aangeeft. Het is geschikt voor nominale variabelen zonder een specifieke volgorde tussen categorieën.
Hier is een voorbeeld van het gebruik van panda's:
importeer panda's als pd
df = pd.DataFrame({'category': ['A', 'B', 'C', 'A']})
one_hot_encoded = pd.get_dummies(df['category'], prefix='category')
Dummy-codering: Dummy-codering is vergelijkbaar met one-hot-codering, maar laat een van de binaire kolommen vallen om multicollineariteitsproblemen in lineaire modellen te voorkomen. Het wordt vaak gebruikt in regressiemodellen waarbij één categorie dient als referentiecategorie.
Hier is een voorbeeld van het gebruik van panda's:
dummy_encoded = pd.get_dummies(df['category'], prefix='category', drop_first=True)
Richtlijnen voor het omgaan met categorische data
Om categorische data correct te verwerken, moet u:
Variabele types begrijpen: Bepaal of categorische variabelen ordinaal of nominaal zijn om de juiste coderingstechniek te kiezen.
Vermijd ordinale verkeerde interpretatie: Wees voorzichtig bij het gebruik van labelcodering voor nominale variabelen, omdat dit onbedoelde ordinaliteit in de data kan introduceren.
Omgaan met hoge kardinaliteit: Voor categorische variabelen met een groot aantal unieke categorieën kunt u technieken overwegen zoals frequentiecodering, doelcodering of dimensionaliteitsreductietechnieken zoals PCA.
Dit alles in aanvulling op de reeds genoemde afhandeling van ontbrekende waarden en het normaliseren van numerieke data.
5. Omgaan met onevenwichtige data
Het omgaan met onevenwichtige data is een veelvoorkomende uitdaging bij machine learning, vooral bij classificatietaken waarbij het aantal instanties in de ene klasse (minderheidsklasse) aanzienlijk lager is dan in de andere klassen (meerderheidsklassen). Onevenwichtige data kunnen een grote impact hebben op modeltraining en -evaluatie, wat leidt tot bevooroordeelde modellen die de meerderheidsklasse bevoordelen en slecht presteren op minderheidsklassen.
Hier zijn enkele belangrijke punten met betrekking tot onevenwichtige data en technieken om ermee om te gaan:
Impact van onevenwichtige data op modelprestaties
Modellen die zijn getraind op onevenwichtige data geven doorgaans prioriteit aan nauwkeurigheid in de meerderheidsklasse, terwijl de minderheidsklasse wordt verwaarloosd. Dit kan leiden tot slechte prestaties op voorspellingen van minderheidsklassen. Ook kunnen statistieken zoals nauwkeurigheid misleidend zijn in onevenwichtige datasets, omdat een hoge nauwkeurigheid kan voortvloeien uit het correct voorspellen van de meerderheidsklasse terwijl de minderheidsklasse wordt genegeerd. Evaluatiemetrieken zoals precisie, recall, F1-score en gebied onder de ROC-curve (AUC-ROC) zijn informatiever voor onevenwichtige datasets in vergelijking met alleen nauwkeurigheid.
Technieken voor het omgaan met onevenwichtige data
De meest voorkomende technieken voor het omgaan met onevenwichtige data zijn over- en ondersampling. Oversampling houdt in dat het aantal gevallen in de minderheidsklasse wordt verhoogd om het in evenwicht te brengen met de meerderheidsklasse. Ondersampling houdt in dat het aantal gevallen in de meerderheidsklasse wordt verminderd om het in evenwicht te brengen met de minderheidsklasse. U kunt ook een hybride aanpak kiezen door over- en ondersampling te combineren.
Er is ook klasseweging, waarbij u de klassegewichten tijdens modeltraining aanpast om fouten in de minderheidsklasse meer te bestraffen dan fouten in de meerderheidsklasse. Dit is alleen nuttig voor algoritmen die klasseweging ondersteunen, zoals logistische regressie of ondersteuning van vectormachines.
Richtlijnen voor het omgaan met onevenwichtige data
Om onevenwichtige data te verwerken, moet u:
Begrijp datadistributie: Analyseer de klasseverdeling in uw dataset om de ernst van de onbalans te bepalen.
Kies de juiste techniek: Selecteer de oversampling-, ondersampling- of hybridetechniek op basis van de grootte van uw dataset, onbalansverhouding en rekenmiddelen.
Evalueer statistieken: Gebruik geschikte evaluatiemetrieken zoals precisie, recall, F1-score of AUC-ROC-curve om de prestaties van het model in beide klassen te beoordelen.
Cross-valideren: Pas technieken toe binnen cross-validatievouwen om datalekken te voorkomen en betrouwbare modelprestatieschattingen te verkrijgen.
Conclusie
Data-voorverwerking helpt ervoor te zorgen dat ML-modellen worden getraind in hoogwaardige, goed geformatteerde data, wat rechtstreeks van invloed is op de prestaties, nauwkeurigheid en generalisatiecapaciteit van het model. Door problemen als ontbrekende waarden, uitschieters, categorische variabelen en klasse-onbalans aan te pakken, stelt data-voorverwerking modellen in staat om beter geïnformeerde en nauwkeurige voorspellingen te doen, wat leidt tot betere besluitvorming in real-world applicaties.
Met de juiste voorverwerking van data kunnen ML-professionals het volledige potentieel van hun data ontsluiten en nauwkeurigere en betrouwbaardere voorspellende modellen bouwen voor verschillende toepassingen in verschillende domeinen.
Om dat echt in de echte wereld te doen, moet u echter eerst een flexibele dataopslagoplossing zoals Pure Storage hebben die u helpt AI en machine learning te versnellen en vooruit te komen met uw AIAIinitiatieven.