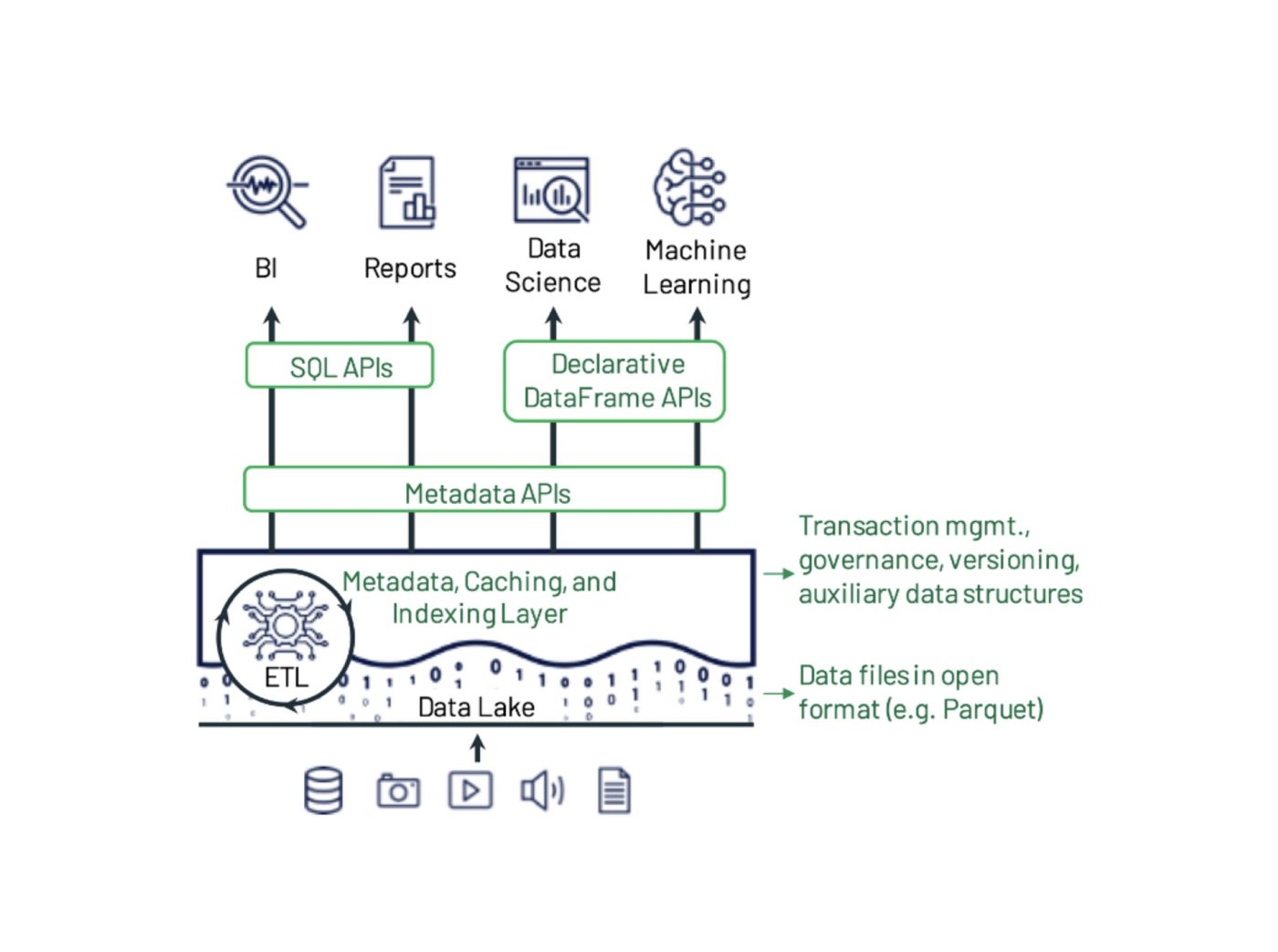
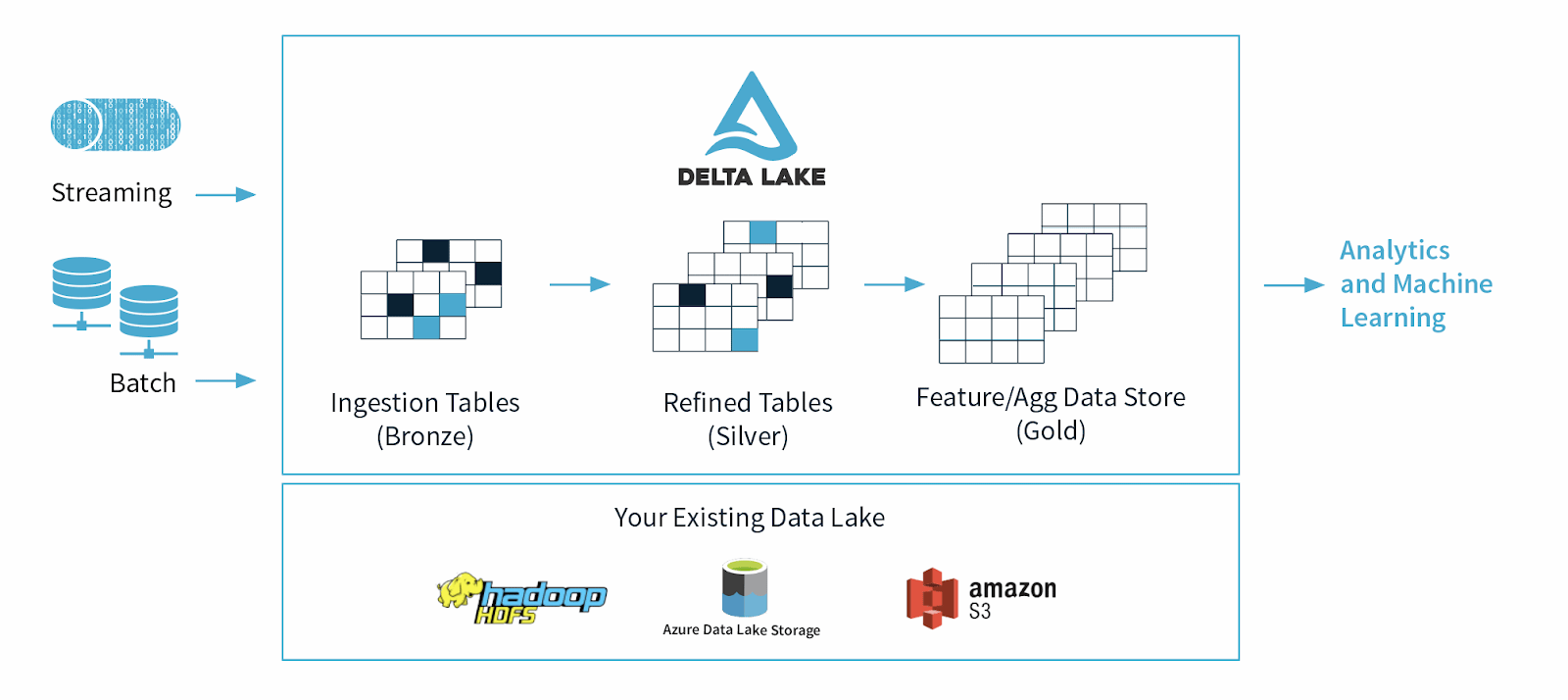
Delta Lake es un marco de almacenamiento de datos de código abierto diseñado para optimizar la confiabilidad y el rendimiento del data lake. Aborda algunos de los problemas comunes que enfrentan los data lakes, como la consistencia de los datos, la calidad de los datos y la falta de transaccionalidad. Su objetivo es proporcionar una solución de almacenamiento de datos que pueda manejar cargas de trabajo escalables de big data en un negocio basado en datos.
Orígenes de Delta Lake
Delta Lake fue lanzado por Databricks, una empresa Apache Spark, en 2019 como un formato de tabla en la nube basado en estándares abiertos y parcialmente código abierto para admitir las características solicitadas a menudo de plataformas de datos modernas, como garantías ACID, reescritores simultáneos, mutabilidad de datos y más.
¿Cuál es el propósito o el uso principal de Delta Lake?
Delta Lake se diseñó para respaldar y mejorar el uso de data lakes, que contienen grandes cantidades de datos estructurados y no estructurados.
Los científicos de datos y analistas de datos utilizan conjuntos de datos para manipular y extraer información valiosa de estos conjuntos de datos masivos. Si bien los data lakes han revolucionado la forma en que administramos los datos, también tienen algunas limitaciones, incluida la calidad de los datos, la consistencia de los datos y, la principal, la falta de esquemas aplicados, lo que dificulta la realización del aprendizaje automático y las operaciones de análisis complejas en los datos sin procesar.
En 2021, científicos de datos tanto académicos como tecnológicos argumentaron que, debido a estas limitaciones, los conjuntos de datos pronto serían reemplazados por “lagos”, que son plataformas abiertas que unifican el almacenamiento de datos y el análisis avanzado.