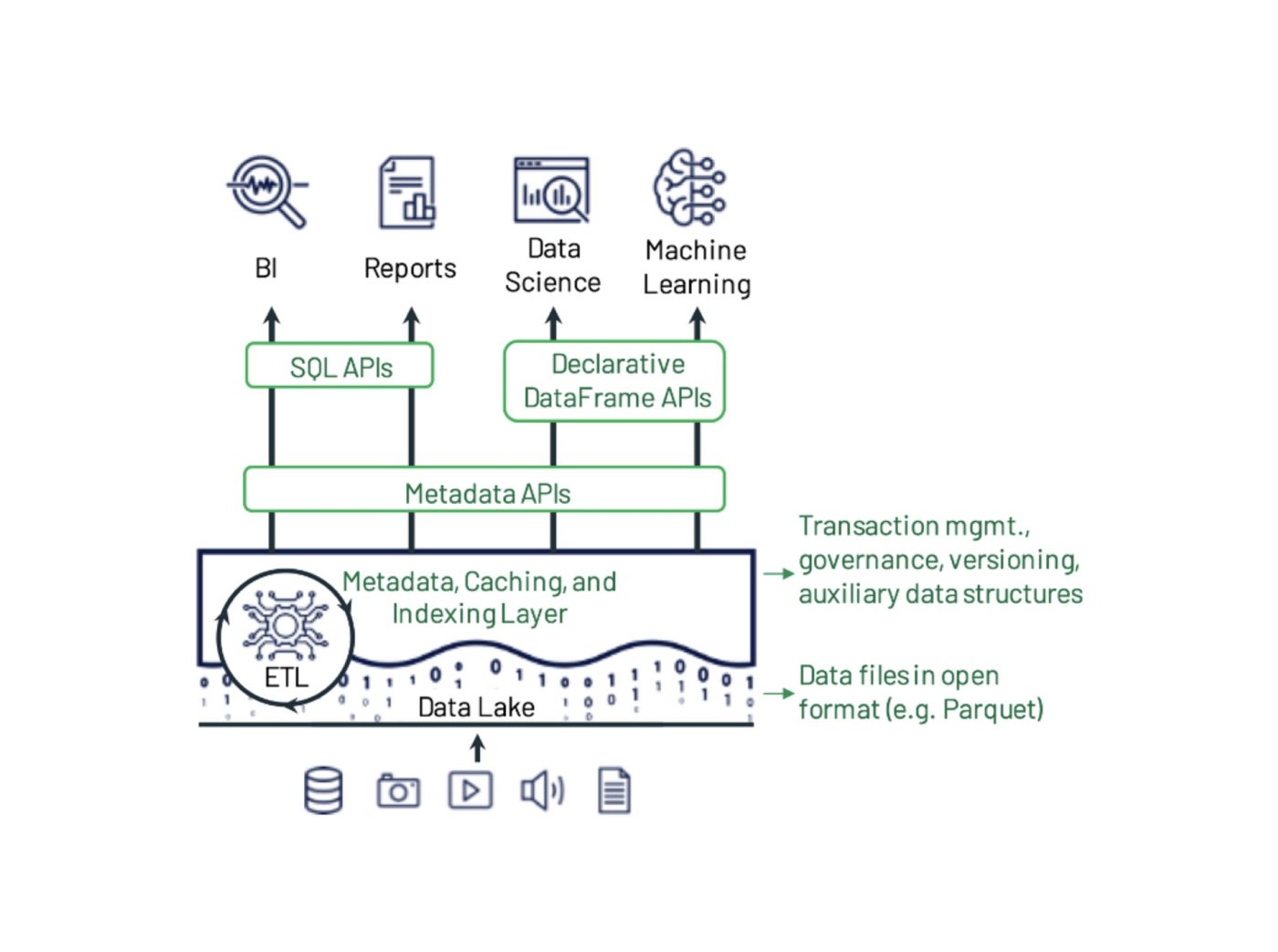
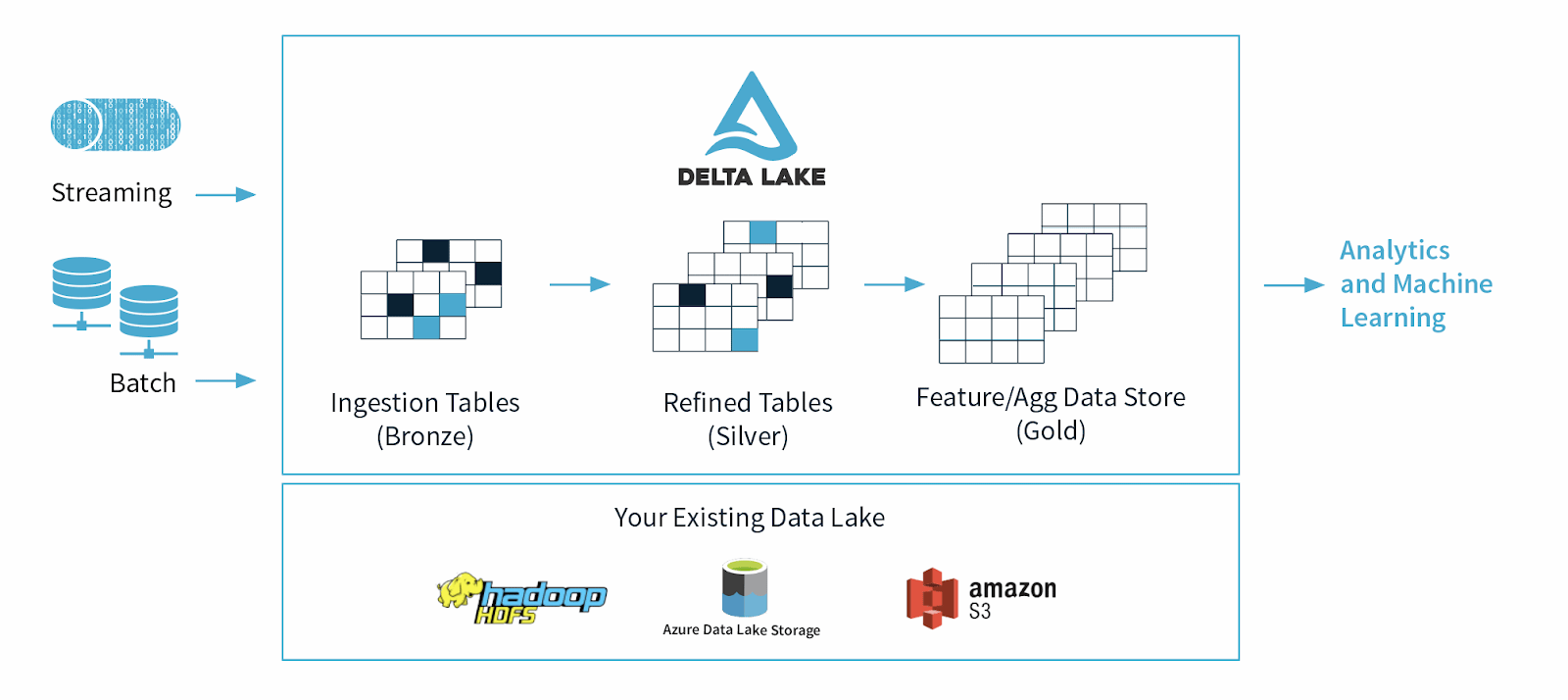
Main Menu
퓨어스토리지의 장점
솔루션
제품
서비스 및 기술지원
유용한 자료
파트너
회사