正規化の適用に関するガイドライン
最小最大スケーリング:最小最大スケーリングは、ニューラル・ネットワークやサポート・ベクター・マシンなどの特定の範囲内の入力特徴量を必要とするアルゴリズムに適しています。外れ値はスケーリングに影響を与える可能性があるため、適切に処理されていることを確認してください。
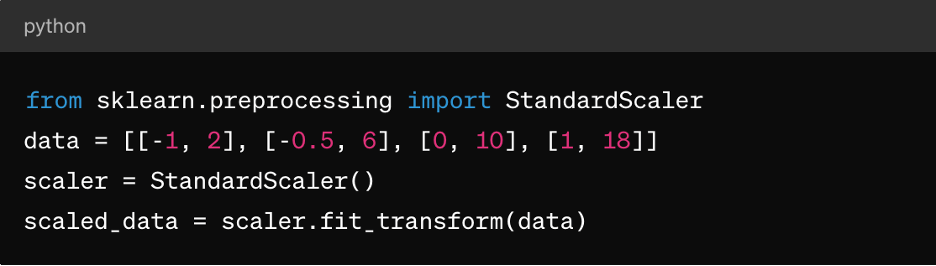
Z スコアの正規化:これは、k-means クラスタリング、線形回帰、ロジスティック回帰などのアルゴリズムに適しています。これにより、平均が0で標準偏差が1の分布が得られ、正規分布したデータを前提とするアルゴリズムに最適です。
スパース(疎)なデータ:疎なデータセット(ほとんどの値がゼロの場合)では、正規化に MaxAbsScaler や RobustScaler などの技術の使用を検討してください。
カテゴリカル・データ:カテゴリカル特徴量については、正規化の前に One-Hot エンコーディングなどの技術を検討し、意味のあるスケーリングを確実にします。
正規化技術の選択は、データの特定の特性と、使用する機械学習アルゴリズムの要件に依存することに注意してください。モデルの性能への影響を実験し、理解することは、正規化を効果的に適用するための重要な要素です。
3. 特徴量スケーリング
特徴量スケーリングは、データセットの独立変数または特徴量の範囲を標準化するために使用されるデータ前処理技術です。特徴量スケーリングの目的は、モデルのトレーニングや分析中に他の特徴量よりも優位に立つことを避けるために、全ての特徴量を同じスケールや範囲にすることです。特徴量スケーリングは、最適化アルゴリズムの収束速度を向上させ、特定の特徴量がモデルに過度の影響を及ぼすのを防ぐことができます。
データ前処理における特徴量スケーリングの役割
特徴量をスケーリングすることで、ML アルゴリズムが全ての特徴量を平等に処理し、より大きなスケールで特徴量に偏向することを防ぎます。また、多くの最適化アルゴリズム(例えば、勾配降下法)が、特徴量スケーリング時により速く収束し、より迅速なモデルのトレーニングにつながるため、収束も強化されます。また、特徴量の大きさの大きな違いによって生じる可能性のある数値の不安定性の問題を防ぐこともできます。最後に、スケーリングにより、モデルの予測に対する特徴量の影響を簡単に解釈できます。
特徴量スケーリングの手法
上記の最小最大スケーリングと Z スコアの正規化に加えて、以下もあります。
MaxAbsScaler:これにより、各要素の最大絶対値がスケーリングされるため、結果として得られる値は -1~1 の範囲になります。テキスト分類やレコメンデーション・システムなど、ゼロの値を保持することが重要な疎なデータに適しています。
RobustScaler:これは、中央値や四分位範囲(IQR)などの外れ値に対して堅牢な統計を使用して、特徴量を拡張します。外れ値や歪んだ分布を含むデータセットに適しています。
特徴量スケーリングの適用に関するガイドライン
以下のような方法で特徴量スケーリングを適用します。
- データが正規分布に従う場合や、線形回帰、ロジスティック回帰、k-means クラスタリングなどのアルゴリズムを使用する場合は、標準化(Z スコア正規化)を適用します。
- ニューラル・ネットワークやサポート・ベクター・マシンなど、特定の範囲内にデータが必要な場合は、正規化(最小最大スケーリング)を適用します。
- テキストデータや高次元の疎な特徴量など、スパース(疎)なデータを扱う場合には、MaxAbsScaler を使用します。
- RobustScaler は、外れ値や正規に分散されていない特徴量を含むデータセットを扱うときに使用します。
特徴量スケーリングを適用する前に、カテゴリ特徴量(特に順序のないカテゴリの場合)はエンコーディング(One-Hot エンコーディングなど)が必要になる場合があることに注意してください。
4. カテゴリカル・データの処理
カテゴリカル変数は、グループやカテゴリを表し、多くの場合、本質的に数値ではないため、モデルのトレーニング中に次のような課題が発生します。
- 数値以外の表現:カテゴリカル変数は通常、文字列やラベルで表され、ほとんどの機械学習アルゴリズムでは直接処理できません。アルゴリズムには、トレーニングと予測のための数値入力が必要です。
- 通常変数と公称変数:カテゴリカル変数には、順序尺度(意味のある順序を持つ)と名義尺度(特定の順序を持たない)があります。順序尺度変数を名義尺度変数として扱ったり、その逆を行ったりすると、モデルの解釈が誤ったものになったり、予測に偏りが生じたりする可能性があります。
- 次元の呪い:カテゴリカル・データを処理する一般的な手法である One-Hot エンコーディングは、特に多数の固有のカテゴリにおいて、データセットの次元性の向上につながります。これにより、モデルの性能に影響が及び、計算の複雑さが増す可能性があります。
カテゴリカル変数のエンコード方法
カテゴリカル変数をエンコードするテクニックには、次のようなものがあります。
ラベル・エンコーディング:ラベル・エンコーディングは、カテゴリカル変数内の各カテゴリに一意の数値ラベルを割り当てます。カテゴリ間に意味のある順序がある場合の順序変数に適しています。
Python の scikit-learn の例を以下に示します。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
encoded_labels = le.fit_transform(['cat', 'dog', 'rabbit', 'dog'])
One-Hot エンコーディング:One-Hot エンコーディングは、カテゴリカル変数内の各カテゴリに対してバイナリ列を作成します。各列は、そのカテゴリの有無を示します。カテゴリ間に特定の順序がない名義変数に適しています。
pandas の使用例を以下に示します。
import pandas as pd
df = pd.DataFrame({'category': ['A', 'B', 'C', 'A']})
one_hot_encoded = pd.get_dummies(df['category'], prefix='category')
ダミー・エンコーディング:ダミー・エンコーディングは One-Hot エンコーディングに似ていますが、線形モデルでの多重共線性の問題を避けるために、1 つのバイナリ列を削除します。これは、1 つのカテゴリが参照カテゴリとして機能する回帰モデルで一般的に使用されます。
pandas の使用例を以下に示します。
dummy_encoded = pd.get_dummies(df['category'], prefix='category', drop_first=True)
カテゴリカル・データの取り扱いに関するガイドライン
カテゴリカル・データを正しく処理するには、次のことを行う必要があります。
変数の種類を理解する:カテゴリカル変数が順序変数か名義変数かを判別し、適切なエンコーディング手法を選択します。
順序の誤解釈を避ける:名義変数に対してラベル・エンコーディングを使用すると、データに意図しない順序が生じる可能性があるため、注意してください。
高いカーディナリティへの対応:固有のカテゴリが多数あるカテゴリカル変数の場合は、頻度エンコーディング、ターゲット・エンコーディング、PCA などの次元削減技術を検討してください。
これは、既に言及した欠損値の取り扱いや数値データの正規化に加えて行われます。
5. 不均衡なデータへの対応
不均衡なデータへの対処は、特に分類タスクにおいてよく直面する課題です。ここでは、一方のクラス(少数クラス)のインスタンス数が他のクラス(多数クラス)よりも大幅に少ない場合に問題となります。不均衡なデータは、モデルのトレーニングや評価に大きな影響を与える可能性があり、多数クラスを優遇し、少数クラスでの性能が低下するバイアスのかかったモデルが生成されることがあります。
不均衡なデータや、データを処理するテクニックに関する重要なポイントは、次のとおりです。
不均衡なデータがモデルの性能に与える影響
不均衡なデータについてトレーニングされたモデルは、少数クラスを無視しながら、多数クラスの精度を優先する傾向があります。これにより、少数クラスの予測において性能が低下する可能性があります。また、精度などの指標は、不均衡なデータセットにおいて誤解を招く可能性があります。なぜなら、高精度は、少数クラスを無視しつつ、多数クラスを正しく予測することに起因する可能性があるからです。精度、再現率、F1 スコア、ROC 曲線下面積(AUC-ROC)などの評価指標は、精度のみの場合と比較して、不均衡なデータセットにとってより有益です。
不均衡なデータを扱うためのテクニック
不均衡なデータを処理する最も一般的な手法は、オーバーサンプリングとアンダーサンプリングです。オーバーサンプリングには、少数クラスのインスタンス数を増やして、多数クラスとのバランスを取ることが含まれます。アンダーサンプリングには、多数クラスのインスタンス数を減らし、少数クラスとのバランスを取ることが含まれます。また、オーバーサンプリングとアンダーサンプリングを組み合わせることで、ハイブリッド・アプローチを取ることもできます。
クラス重み付けもあります。モデルのトレーニング中にクラスの重みを調整して、少数クラスのエラーを多数クラスのエラー以上に罰します。これは、ロジスティック回帰やサポート・ベクター・マシンなど、クラスの重み付けをサポートするアルゴリズムにのみ役立ちます。
不均衡なデータの取り扱いに関するガイドライン
不均衡なデータを処理するには、次のことを行う必要があります。
データの分布を理解する:データセット内のクラス分布を分析して、不均衡の重大性を判断します。
適切な技術を選択してください。オーバーサンプリング、アンダーサンプリング、ハイブリッド技術は、データセットのサイズ、不均衡率、計算リソースに基づいて選択します。
評価指標:精度、再現率、F1 スコア、AUC-ROC 曲線などの適切な評価指標を使用して、両方のクラスでモデルの性能を評価します。
交差検証:交差検証の枠内で技術を適用することで、データ漏洩を回避し、信頼性の高いモデル性能の見積もりを得ることができます。
まとめ
データ前処理は、ML モデルが高品質で適切にフォーマットされたデータについてトレーニングされていることを保証し、モデルの性能、精度、一般化能力に直接影響を与えます。欠損値、外れ値、カテゴリカル変数、クラスの不均衡などの問題に対処することで、データ前処理により、モデルがより多くの情報に基づいた正確な予測を行うことができ、実際のアプリケーションにおける意思決定が向上します。
ML の実践者は、適切なデータ前処理により、データの可能性を最大限に引き出し、ドメイン間のさまざまなアプリケーションに対して、より正確で信頼性の高い予測モデルを構築できます。
しかし、現実世界でこれを実現するには、AI や機械学習を加速し、エンタープライズ AI イニシアチブを前進させるピュア・ストレージのような柔軟なデータ・ストレージ・ソリューションが必要です。