Linee guida per l'applicazione della normalizzazione
Scalabilità min-max: La scalabilità Min-max è adatta agli algoritmi che richiedono funzionalità di input che rientrino in un intervallo specifico, come le reti neurali e le macchine vettoriali di supporto. Assicurarsi che gli outlier siano gestiti in modo appropriato, in quanto possono influire sulla scalabilità.
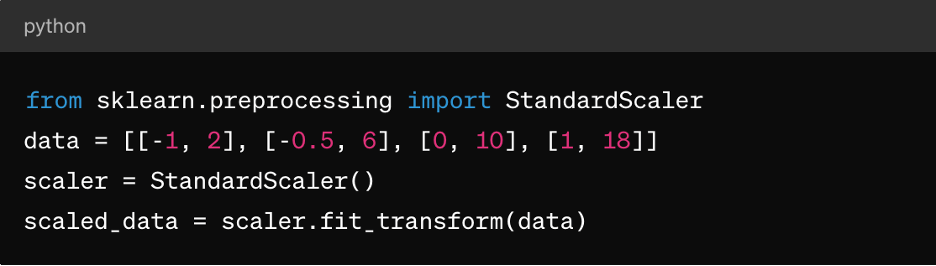
Normalizzazione del punteggio Z: È adatto ad algoritmi come il k-means clustering, la regressione lineare e la regressione logistica. Si traduce in una distribuzione centrata intorno a 0 con una deviazione standard di 1, che la rende ideale per gli algoritmi che presuppongono dati distribuiti normalmente.
Dati sparsi: Per i set di dati sparsi (dove la maggior parte dei valori è pari a zero), è consigliabile utilizzare tecniche come MaxAbsScaler o RobustScaler per la normalizzazione.
Dati categorici: Per le funzionalità categoriche, considera tecniche come la codifica one-hot prima della normalizzazione per garantire una scalabilità significativa.
È importante notare che la scelta della tecnica di normalizzazione dipende dalle caratteristiche specifiche dei dati e dai requisiti dell'algoritmo di machine learning che si intende utilizzare. La sperimentazione e la comprensione dell'impatto sulle performance dei modelli sono aspetti chiave per applicare la normalizzazione in modo efficace.
3. Scalabilità delle funzionalità
La scalabilità delle funzionalità è una tecnica di pre-elaborazione dei dati utilizzata per standardizzare la gamma di variabili o funzionalità indipendenti di un dataset. L'obiettivo della scalabilità delle funzionalità è quello di portare tutte le funzionalità su una scala o un intervallo simile per evitare che una caratteristica prevalga su altre durante l'addestramento o l'analisi dei modelli. La scalabilità delle funzionalità può migliorare la velocità di convergenza degli algoritmi di ottimizzazione ed evitare che determinate funzionalità abbiano un'influenza indebita sul modello.
Ruolo della scalabilità delle funzionalità nella pre-elaborazione dei dati
Le funzionalità di scalabilità garantiscono che gli algoritmi ML trattino tutte le funzionalità allo stesso modo, evitando distorsioni verso le funzionalità con scale più grandi. Inoltre, migliora le convergenze, poiché molti algoritmi di ottimizzazione (ad esempio, la discesa a gradiente) convergono più velocemente quando le funzionalità vengono scalate, portando a un addestramento più rapido dei modelli. Può anche prevenire problemi di instabilità numerica che possono insorgere a causa di grandi differenze di grandezza delle funzionalità. Infine, la scalabilità può semplificare l'interpretazione dell'impatto delle funzionalità sulle previsioni del modello.
Metodi di scalabilità delle funzionalità
Oltre alla scala min-max e alla normalizzazione del punteggio Z descritte sopra, sono disponibili anche:
MaxAbsScaler: In questo modo ogni caratteristica viene scalata in base al suo valore assoluto massimo, quindi i valori risultanti variano tra -1 e 1. È adatto per i dati sparsi in cui è importante preservare zero voci, come nella classificazione del testo o nei sistemi di raccomandazione.
Scalabilità solida: Questo utilizza statistiche solide per gli outlier, come la mediana e l'intervallo interquartile (IQR), per scalare le funzionalità. È adatto per dataset contenenti outlier o distribuzioni alterate.
Linee guida per l'applicazione della scalabilità delle funzionalità
Per applicare la scalabilità delle funzionalità:
- Applicare la standardizzazione (normalizzazione del punteggio Z) quando i dati seguono una distribuzione normale o quando utilizzano algoritmi come la regressione lineare, la regressione logistica o il k-means clustering.
- Applica la normalizzazione (scala min-max) quando hai bisogno che i dati rientrino in un intervallo specifico, come le reti neurali o le macchine vettoriali di supporto.
- Usa MaxAbsScaler per gestire dati sparsi, come i dati di testo o le funzionalità sparse ad alta dimensione.
- Usa RobustScaler per gestire dataset contenenti outlier o funzionalità distribuite in modo non normale.
Tieni presente che le funzionalità categoriche possono richiedere la codifica (ad esempio, la codifica one-hot) prima di applicare la scalabilità delle funzionalità, specialmente se sono nominali (categorie non ordinate).
4. Gestione dei dati categorici
Le variabili categoriche rappresentano gruppi o categorie e sono spesso di natura non numerica, ponendo sfide durante l'addestramento dei modelli, tra cui:
- Rappresentazione non numerica: Le variabili categoriche sono in genere rappresentate utilizzando stringhe o etichette, che la maggior parte degli algoritmi di machine learning non è in grado di elaborare direttamente. Gli algoritmi richiedono input numerici per l'addestramento e le previsioni.
- Variabili normali e nominali: Le variabili categoriche possono essere ordinali (con un ordine significativo) o nominali (senza un ordine specifico). Trattare le variabili ordinali come nominali o viceversa può portare a interpretazioni errate dei modelli o a previsioni distorte.
- Maledizione della dimensionalità: La codifica one-hot, una tecnica comune per la gestione dei dati categorici, può portare a un aumento della dimensionalità del set di dati, specialmente con un elevato numero di categorie univoche. Ciò può influire sulle performance del modello e aumentare la complessità computazionale.
Tecniche di codifica delle variabili categoriche
Le tecniche di codifica delle variabili categoriche includono:
Codifica delle etichette: La codifica delle etichette assegna un'etichetta numerica univoca a ciascuna categoria in una variabile categorica. È adatto per le variabili ordinali in cui esiste un ordine significativo tra le categorie.
Ecco un esempio di utilizzo dello scikit-learn di Python:
da sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
coded_labels = le.fit_transform(['cat', 'cane', 'coniglio', 'cane'])
Codifica one-hot: La codifica one-hot crea colonne binarie per ogni categoria in una variabile categorica, in cui ogni colonna indica la presenza o l'assenza di tale categoria. È adatto per le variabili nominali senza un ordine specifico tra le categorie.
Ecco un esempio di panda:
importare panda come pd
df = pd.DataFrame({'category': ['A', 'B', 'C', 'A']})
one_hot_encoded = pd.get_dummies(df['category'], prefisso='category')
Codifica fittizia: La codifica fittizia è simile alla codifica one-hot, ma elimina una delle colonne binarie per evitare problemi di multicollinearità nei modelli lineari. È comunemente utilizzato nei modelli di regressione in cui una categoria funge da categoria di riferimento.
Ecco un esempio di panda:
dummy_encoded = pd.get_dummies(df['category'], prefisso='category', drop_first=True)
Linee guida per la gestione dei dati categorici
Per gestire correttamente i dati categorici, è necessario:
Comprendere i tipi di variabili: Determinare se le variabili categoriche sono ordinali o nominali per scegliere la tecnica di codifica appropriata.
Evitare interpretazioni errate ordinali: Prestare attenzione quando si utilizza la codifica delle etichette per le variabili nominali, in quanto può introdurre ordinalità involontaria nei dati.
Affronta l'alta cardinalità: Per le variabili categoriche con un elevato numero di categorie univoche, considerare tecniche come la codifica della frequenza, la codifica della destinazione o le tecniche di riduzione della dimensionalità come PCA.
Tutto questo si aggiunge alla già citata gestione dei valori mancanti e alla normalizzazione dei dati numerici.
5. Gestione dei dati sbilanciati
Gestire i dati sbilanciati è una sfida comune nel machine learning, specialmente nelle attività di classificazione in cui il numero di istanze in una classe (classe di minoranza) è significativamente inferiore rispetto alle altre classi (classi di maggioranza). I dati sbilanciati possono avere un impatto profondo sull'addestramento e sulla valutazione dei modelli, portando a modelli disorientati che favoriscono la maggioranza e offrono performance scarse sulle classi di minoranza.
Ecco alcuni punti chiave relativi ai dati sbilanciati e alle tecniche di gestione:
Impatto dei dati sbilanciati sulle performance dei modelli
I modelli formati su dati sbilanciati tendono a dare priorità alla precisione nella classe di maggioranza, trascurando al contempo la classe di minoranza. Ciò può portare a performance scadenti per le previsioni di minoranze. Inoltre, metriche come l'accuratezza possono essere fuorvianti nei dataset sbilanciati, poiché una precisione elevata può derivare dalla previsione corretta della classe di maggioranza, ignorando al contempo la classe di minoranza. Le metriche di valutazione come precisione, richiamo, F1-score e area sotto la curva ROC (AUC-ROC) sono più informative per i dataset sbilanciati rispetto alla sola precisione.
Tecniche di gestione dei dati sbilanciati
Le tecniche più comuni per la gestione dei dati sbilanciati sono l'oversampling e l'undersampling. L'ipercampionamento implica l'aumento del numero di istanze nella classe di minoranza per bilanciarlo con la classe di maggioranza. Il sottocampionamento comporta la riduzione del numero di istanze nella classe di maggioranza per bilanciarle con la classe di minoranza. Puoi anche adottare un approccio ibrido combinando il sovracampionamento e il sottocampionamento.
È inoltre disponibile una ponderazione della classe, in cui si regolano i pesi della classe durante l'addestramento dei modelli per penalizzare gli errori nella classe di minoranza piuttosto che gli errori nella classe di maggioranza. Ciò è utile solo per gli algoritmi che supportano la ponderazione delle classi, come la regressione logistica o il supporto delle macchine vettoriali.
Linee guida per la gestione dei dati sbilanciati
Per gestire i dati sbilanciati, è necessario:
Comprendere la distribuzione dei dati: Analizzare la distribuzione delle classi nel dataset per determinare la gravità dello squilibrio.
Scegliere la tecnica appropriata: Seleziona la tecnica di sovracampionamento, sottocampionamento o ibrida in base alle dimensioni del set di dati, al rapporto di squilibrio e alle risorse computazionali.
Valuta le metriche: Utilizza metriche di valutazione appropriate come precisione, richiamo, F1-score o curva AUC-ROC per valutare le performance del modello su entrambe le classi.
Convalida incrociata: Applicare tecniche all'interno di fold di convalida incrociata per evitare la perdita di dati e ottenere stime affidabili delle performance del modello.
Conclusione
La pre-elaborazione dei dati aiuta a garantire che i modelli ML siano formati su dati di alta qualità e adeguatamente formattati, il che influisce direttamente sulle performance, sulla precisione e sulla capacità di generalizzazione del modello. Risolvendo problemi come valori mancanti, outlier, variabili categoriche e squilibri di classe, la pre-elaborazione dei dati consente ai modelli di fare previsioni più informate e accurate, portando a un migliore processo decisionale nelle applicazioni del mondo reale.
Grazie a una corretta pre-elaborazione dei dati, i professionisti del ML possono liberare tutto il potenziale dei propri dati e creare modelli predittivi più precisi e affidabili per varie applicazioni tra domini.
Tuttavia, per farlo realmente nel mondo reale, devi prima disporre di una soluzione di data storage flessibile come Pure Storage che ti aiuti ad accelerare l'AI e il machine learning e ad andare avanti con le tue iniziative di AI aziendale.