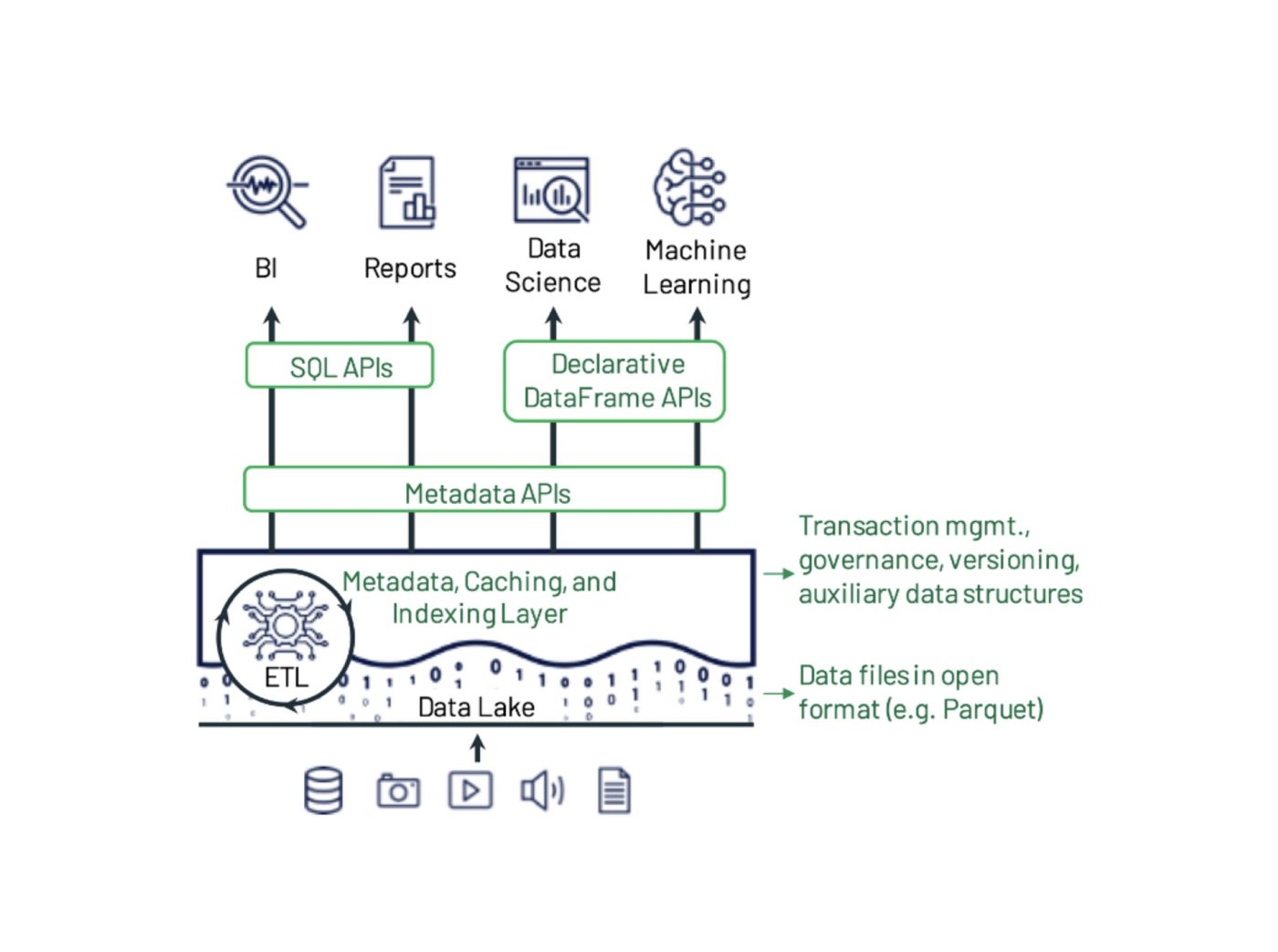
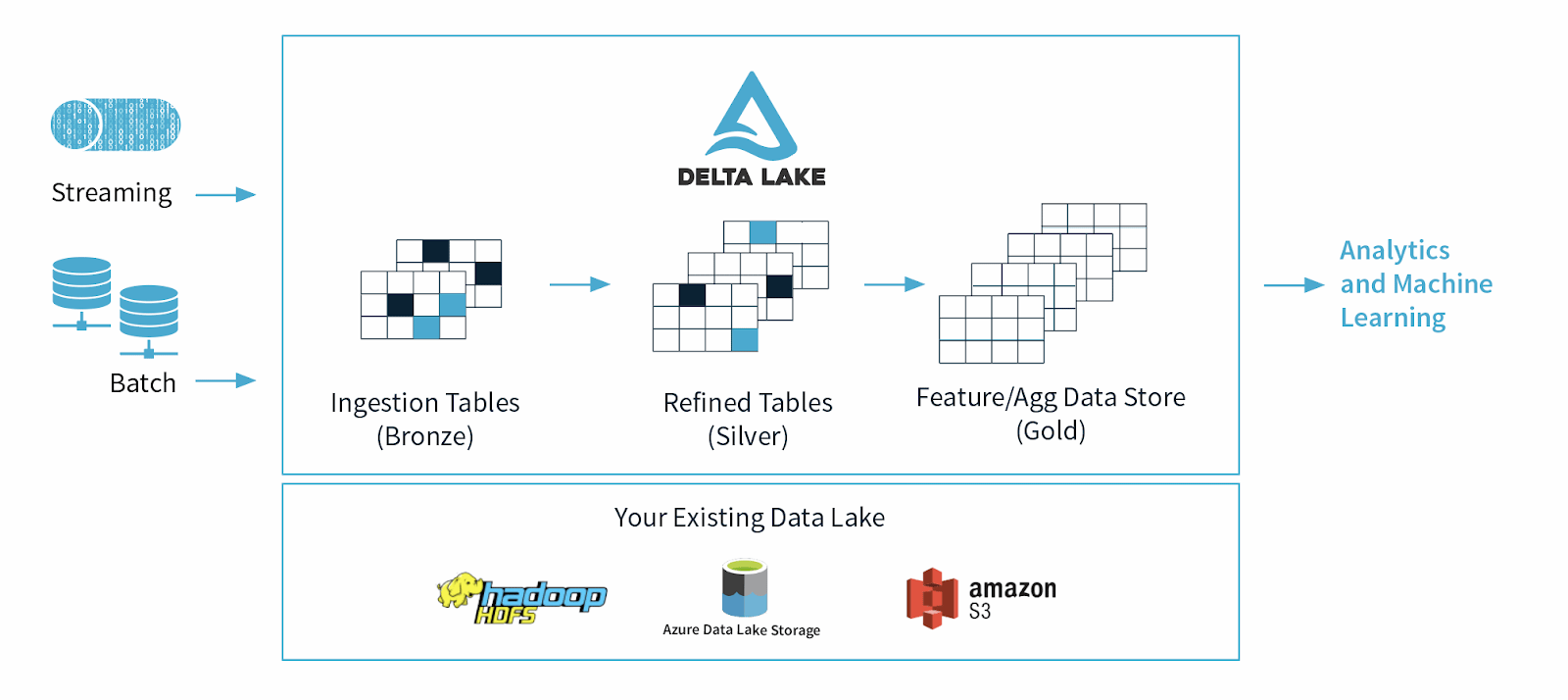
Delta Lake est un cadre de stockage de données open source conçu pour optimiser la fiabilité et les performances des lacs de données. Il traite certains des problèmes courants auxquels sont confrontés les lacs de données, tels que la cohérence des données, la qualité des données et le manque de transactionnalité. Son objectif est de fournir une solution de stockage de données capable de gérer des charges de travail Big Data évolutives dans une entreprise axée sur les données.
Delta Lake Origins
Delta Lake a été lancé par Databricks, une société Apache Spark, en 2019 sous la forme d’un format de table cloud basé sur des normes ouvertes et partiellement open source pour prendre en charge les fonctionnalités demandées par les plateformes de données modernes, telles que les garanties ACID, les réécritures simultanées, la mutabilité des données, etc.
Quel est l’objectif ou l’utilisation principale de Delta Lake ?
Delta Lake a été conçu pour prendre en charge et améliorer l’utilisation des lacs de données, qui contiennent d’énormes quantités de données structurées et non structurées.
Les spécialistes des données et les analystes de données utilisent des lacs de données pour manipuler et extraire des informations précieuses de ces ensembles de données massifs. Bien que les lacs de données aient révolutionné la façon dont nous gérons les données, ils s’accompagnent également de certaines limites, notamment la qualité des données, la cohérence des données et, le premier, un manque de schémas appliqués, ce qui rend difficile l’apprentissage machine et les opérations d’analytique complexes sur les données brutes.
En 2021, des spécialistes des données du monde universitaire et de la technologie ont fait valoir que, en raison de ces limitations, les lacs de données seraient bientôt remplacés par des « lacs », des plateformes ouvertes qui unifient l’entreposage de données et l’analytique avancée.