Directives pour appliquer la normalisation
Évolutivité min-max : La mise à l’échelle min-max convient aux algorithmes qui nécessitent des fonctionnalités d’entrée comprises dans une plage spécifique, comme les réseaux neuronaux et les machines vectorielles prises en charge. Assurez-vous que les valeurs aberrantes sont gérées de manière appropriée, car elles peuvent affecter l’évolutivité.
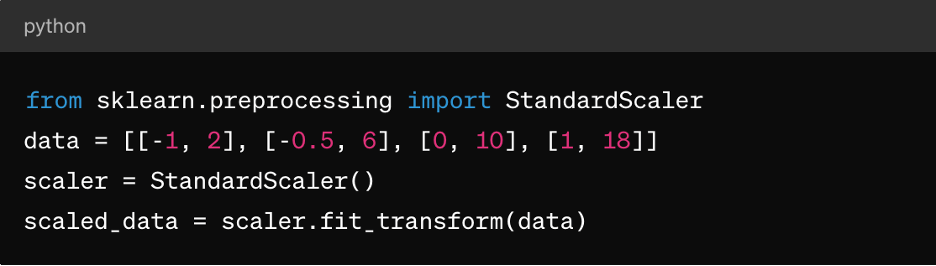
Normalisation du score Z : Cela convient aux algorithmes tels que le clustering k-means, la régression linéaire et la régression logistique. Il en résulte une distribution centrée autour de 0 avec un écart type de 1, ce qui le rend idéal pour les algorithmes qui supposent des données normalement distribuées.
Données éparses : Pour les jeux de données épars (où la plupart des valeurs sont nulles), envisagez d’utiliser des techniques comme MaxAbsScaler ou RobustScaler pour la normalisation.
Données catégorielles : Pour les fonctionnalités catégorielles, considérez des techniques comme le codage à chaud avant la normalisation pour garantir une mise à l’échelle significative.
Il est important de noter que le choix de la technique de normalisation dépend des caractéristiques spécifiques de vos données et des exigences de l’algorithme d’apprentissage machine que vous prévoyez d’utiliser. L’expérimentation et la compréhension de l’impact sur les performances du modèle sont des aspects essentiels pour appliquer efficacement la normalisation.
3. Mise à l’échelle des fonctionnalités
La mise à l’échelle des variables est une technique de prétraitement des données utilisée pour standardiser la plage de variables ou de fonctionnalités indépendantes d’un ensemble de données. L’objectif de la mise à l’échelle des fonctionnalités est d’amener toutes les fonctionnalités à une échelle ou à une plage similaire afin d’éviter qu’une fonctionnalité domine les autres pendant l’entraînement ou l’analyse du modèle. La mise à l’échelle des fonctionnalités peut améliorer la vitesse de convergence des algorithmes d’optimisation et empêcher certaines fonctionnalités d’avoir une influence excessive sur le modèle.
Rôle de la mise à l’échelle des fonctionnalités dans le prétraitement des données
Grâce aux fonctionnalités de mise à l’échelle, les algorithmes d’ML traitent toutes les fonctionnalités de manière égale, ce qui évite les biais vers les fonctionnalités à plus grande échelle. Il améliore également les convergences, car de nombreux algorithmes d’optimisation (par exemple, la descente en gradient) convergent plus rapidement lorsque les fonctionnalités sont mises à l’échelle, ce qui accélère l’entraînement des modèles. Elle peut également éviter les problèmes d’instabilité numérique pouvant survenir en raison de différences importantes dans les amplitudes des fonctionnalités. Enfin, la mise à l’échelle peut faciliter l’interprétation de l’impact des fonctionnalités sur les prédictions du modèle.
Méthodes de mise à l’échelle des fonctionnalités
En plus de l’évolution min-max décrite ci-dessus et de la normalisation du score Z, il existe également :
MaxAbsScaler : Chaque entité est ainsi mise à l’échelle en fonction de sa valeur absolue maximale, de sorte que les valeurs obtenues se situent entre -1 et 1. Il convient aux données éparses où il est important de préserver l’absence d’entrées, par exemple dans les systèmes de classification du texte ou de recommandation.
RobustScaler : Elle utilise des statistiques robustes par rapport aux valeurs aberrantes, telles que la médiane et l’intervalle interquartile (IQR), pour faire évoluer les fonctionnalités. Il convient aux ensembles de données contenant des valeurs aberrantes ou des distributions biaisées.
Directives pour appliquer la mise à l’échelle des fonctionnalités
Pour appliquer la mise à l’échelle des fonctionnalités :
- Appliquer la standardisation (normalisation du score Z) lorsque les données suivent une distribution normale ou lorsqu’elles utilisent des algorithmes tels que la régression linéaire, la régression logistique ou le clustering k-moyennes.
- Appliquer la normalisation (évolutivité min-max) lorsque vous avez besoin que les données se trouvent dans une plage spécifique, comme les réseaux neuronaux ou les machines vectorielles prises en charge.
- Utilisez MaxAbsScaler lorsque vous traitez des données éparses, telles que des données textuelles ou des fonctionnalités éparses en grandes dimensions.
- Utilisez RobustScaler lorsque vous traitez des ensembles de données contenant des valeurs aberrantes ou des fonctionnalités distribuées de manière anormale.
N’oubliez pas que les fonctionnalités catégorielles peuvent nécessiter un codage (par exemple, un codage à chaud) avant d’appliquer une mise à l’échelle des fonctionnalités, en particulier si elles sont nominales (catégories non classées).
4. Gestion des données catégorielles
Les variables catégorielles représentent des groupes ou des catégories et sont souvent de nature non numérique, ce qui pose des difficultés pendant l’entraînement du modèle, notamment :
- Représentation non numérique : Les variables catégorielles sont généralement représentées à l’aide de chaînes ou d’étiquettes, que la plupart des algorithmes d’apprentissage machine ne peuvent pas traiter directement. Les algorithmes nécessitent des entrées numériques pour l’entraînement et les prédictions.
- Variables ordinales et nominales : Les variables catégorielles peuvent être ordinales (avec un ordre significatif) ou nominales (sans ordre spécifique). Le traitement des variables ordinales comme nominales ou inversement peut entraîner des interprétations incorrectes du modèle ou des prédictions biaisées.
- Malédiction de la dimensionnalité : L’encodage à chaud, une technique courante de traitement des données catégorielles, peut entraîner une augmentation de la dimensionnalité de l’ensemble de données, en particulier avec un grand nombre de catégories uniques. Cela peut avoir un impact sur les performances du modèle et augmenter la complexité de calcul.
Techniques de codage des variables catégorielles
Les techniques de codage des variables catégorielles sont les suivantes :
Encodage des étiquettes : Le codage d’étiquette attribue une étiquette numérique unique à chaque catégorie dans une variable catégorielle. Il convient aux variables ordinales où il existe un ordre significatif entre les catégories.
Voici un exemple de l’apprentissage scikit de Python :
depuis sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
encoded_labels = le.fit_transform(['cat', 'chien', 'lapin', 'chien'])
Encodage à chaud : Le codage à chaud crée des colonnes binaires pour chaque catégorie dans une variable catégorielle, où chaque colonne indique la présence ou l’absence de cette catégorie. Il convient aux variables nominales sans ordre spécifique entre les catégories.
Voici un exemple de pandas :
importer des pandas sous forme de pd
df = pd.DataFrame({'category' : ['A', 'B', 'C', 'A']})
one_hot_encoded = pd.get_dummies(df['category'], préfixe='category')
Encodage factice : L’encodage factice est similaire à l’encodage à chaud, mais supprime l’une des colonnes binaires pour éviter les problèmes de multicolinéarité dans les modèles linéaires. Il est couramment utilisé dans les modèles de régression où une catégorie sert de catégorie de référence.
Voici un exemple de pandas :
dummy_encoded = pd.get_dummies(df['category'], préfixe='category', drop_first=True)
Directives pour le traitement des données catégorielles
Pour gérer correctement les données catégorielles, vous devez :
Comprendre les types de variables : Déterminez si les variables catégorielles sont ordinales ou nominales pour choisir la technique d’encodage appropriée.
Évitez les erreurs d’interprétation ordinales : Soyez prudent lorsque vous utilisez l’encodage d’étiquette pour les variables nominales, car cela peut introduire une ordinaire involontaire dans les données.
Faites face à une forte cardinalité : Pour les variables catégorielles avec un grand nombre de catégories uniques, il faut envisager des techniques telles que le codage de fréquence, le codage cible ou les techniques de réduction de dimensionnalité telles que la PCA.
Tout cela s’ajoute au traitement déjà mentionné des valeurs manquantes et à la normalisation des données numériques.
5. Gérer les données déséquilibrées
Gérer les données déséquilibrées est un défi courant dans l’apprentissage machine, en particulier dans les tâches de classification où le nombre d’instances dans une classe (classe minoritaire) est nettement inférieur à celui des autres classes (classes majoritaires). Les données déséquilibrées peuvent avoir un impact profond sur l’entraînement et l’évaluation des modèles, ce qui conduit à des modèles biaisés qui favorisent la classe majoritaire et fonctionnent mal sur les classes minoritaires.
Voici quelques points clés concernant le déséquilibre des données et les techniques de traitement :
Impact des données déséquilibrées sur les performances du modèle
Les modèles entraînés sur des données déséquilibrées ont tendance à donner la priorité à la précision sur la classe majoritaire, tout en négligeant la classe minoritaire. Cela peut entraîner de mauvaises performances sur les prévisions de classe minoritaire. De plus, des mesures comme la précision peuvent être trompeuses dans les ensembles de données déséquilibrés, car une haute précision peut résulter de la prédiction correcte de la classe majoritaire tout en ignorant la classe minoritaire. Les indicateurs d’évaluation tels que la précision, le rappel, F1-score et l’aire sous la courbe ROC (ASC-ROC) sont plus instructifs pour les ensembles de données déséquilibrés que pour la précision seule.
Techniques de traitement des données déséquilibrées
Les techniques les plus courantes de gestion des données déséquilibrées sont le sur-échantillonnage et le sous-échantillonnage. Le suréchantillonnage implique d’augmenter le nombre d’instances dans la classe minoritaire pour l’équilibrer avec la classe majoritaire. Le sous-échantillonnage implique de réduire le nombre d’instances dans la classe majoritaire pour l’équilibrer avec la classe minoritaire. Vous pouvez également adopter une approche hybride en combinant le sur-échantillonnage et le sous-échantillonnage.
Il y a également la pondération des classes, où vous ajustez les pondérations des classes pendant l’entraînement du modèle pour pénaliser les erreurs sur la classe minoritaire plus que les erreurs sur la classe majoritaire. Cela n’est utile que pour les algorithmes qui prennent en charge la pondération des classes, comme la régression logistique ou les machines vectorielles.
Directives de gestion des données déséquilibrées
Pour gérer les données déséquilibrées, vous devez :
Comprendre la distribution des données : Analysez la répartition des classes dans votre ensemble de données pour déterminer la gravité du déséquilibre.
Choisissez la technique appropriée : Sélectionnez la technique de suréchantillonnage, de sous-échantillonnage ou hybride en fonction de la taille de votre ensemble de données, du taux de déséquilibre et des ressources de calcul.
Évaluer les indicateurs : Utilisez des indicateurs d’évaluation appropriés comme la précision, le rappel, F1-score ou la courbe ASC-ROC pour évaluer les performances du modèle sur les deux classes.
Validation croisée : Appliquer des techniques dans des tests de validation croisée pour éviter les fuites de données et obtenir des estimations fiables des performances du modèle.
Conclusion
Le prétraitement des données permet de s’assurer que les modèles ML sont entraînés sur des données de haute qualité et correctement formatées, ce qui a un impact direct sur les performances, la précision et la capacité de généralisation du modèle. En résolvant des problèmes tels que les valeurs manquantes, les valeurs aberrantes, les variables catégorielles et le déséquilibre des classes, le prétraitement des données permet aux modèles de faire des prédictions plus éclairées et précises, ce qui permet de prendre de meilleures décisions dans des applications réelles.
Avec un prétraitement des données approprié, les praticiens de l’ML peuvent libérer tout le potentiel de leurs données et créer des modèles prédictifs plus précis et plus fiables pour diverses applications dans différents domaines.
Mais pour y parvenir réellement, vous devez d’abord disposer d’une solution de stockage de données flexible, telle que Pure Storage, qui vous aide à accélérer l’AI et l’apprentissage machine et à prendre de l’avance sur vos initiatives d’AI d’entreprise.