Data Lake ou Data Hub
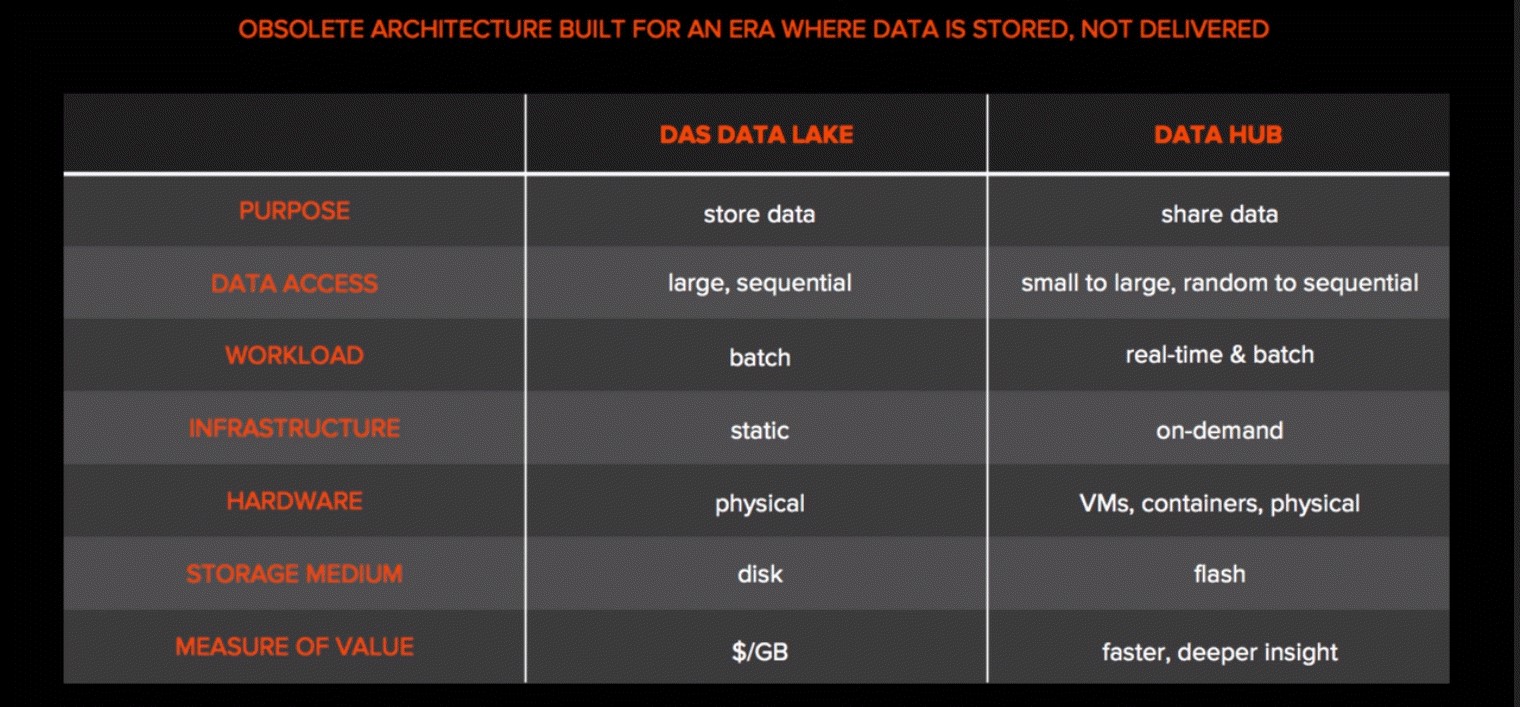
La conception d’un Data Hub diffère grandement de celle d’un Data Lake. Le Data Lake est conçu pour stocker des données de manière aussi efficace que possible et s’appuie sur des technologies traditionnelles telles que le stockage DAS. Le principal problème du Data Lake est qu’il crée des silos de données, ce qui empêche de combiner les jeux de données en un ensemble cohérent et adapté aux besoins de l’analytique.
Un Data Hub est une architecture de stockage moderne, centrée sur les données, qui alimente l'analytique et l'IA . Il permet ainsi aux entreprises de consolider et de partager leurs données. Contrairement aux Data Lakes et aux architectures DAS, conçues pour stocker des données, un Data Hub est pensé pour les partager et les mettre à disposition en temps réel en assurant des performances multidimensionnelles.
Pourquoi les Data Lakes sont-ils en train de disparaître ?
Si les Data Lakes sont aujourd’hui dépassés, c’est aussi parce qu’ils reposent sur un principe obsolète selon lequel toutes les données non structurées doivent être stockées. Certaines données sont stockées dans des entrepôts de données, d’autres sont perdues dans les Data Lakes. Les données n’étant plus unifiées, la vitesse d’exploitation des données en est directement affectée. Pourquoi est-il si difficile pour les systèmes de stockage traditionnels d’unifier les données sur une même plateforme ? Chaque application pose différentes exigences en termes de données, d’où la prolifération des silos. Le moment est venu de redéfinir le stockage des données.
Les données sont la source d'énergie des entreprises modernes. Pourtant, la plupart des données sont stockées en silos, fragmentées et hors de portée des applications d’analytique et d’IA (Intelligence Artificielle). L’intelligence moderne requiert une architecture destinée non seulement à stocker les données, mais aussi à les partager et à les exploiter.