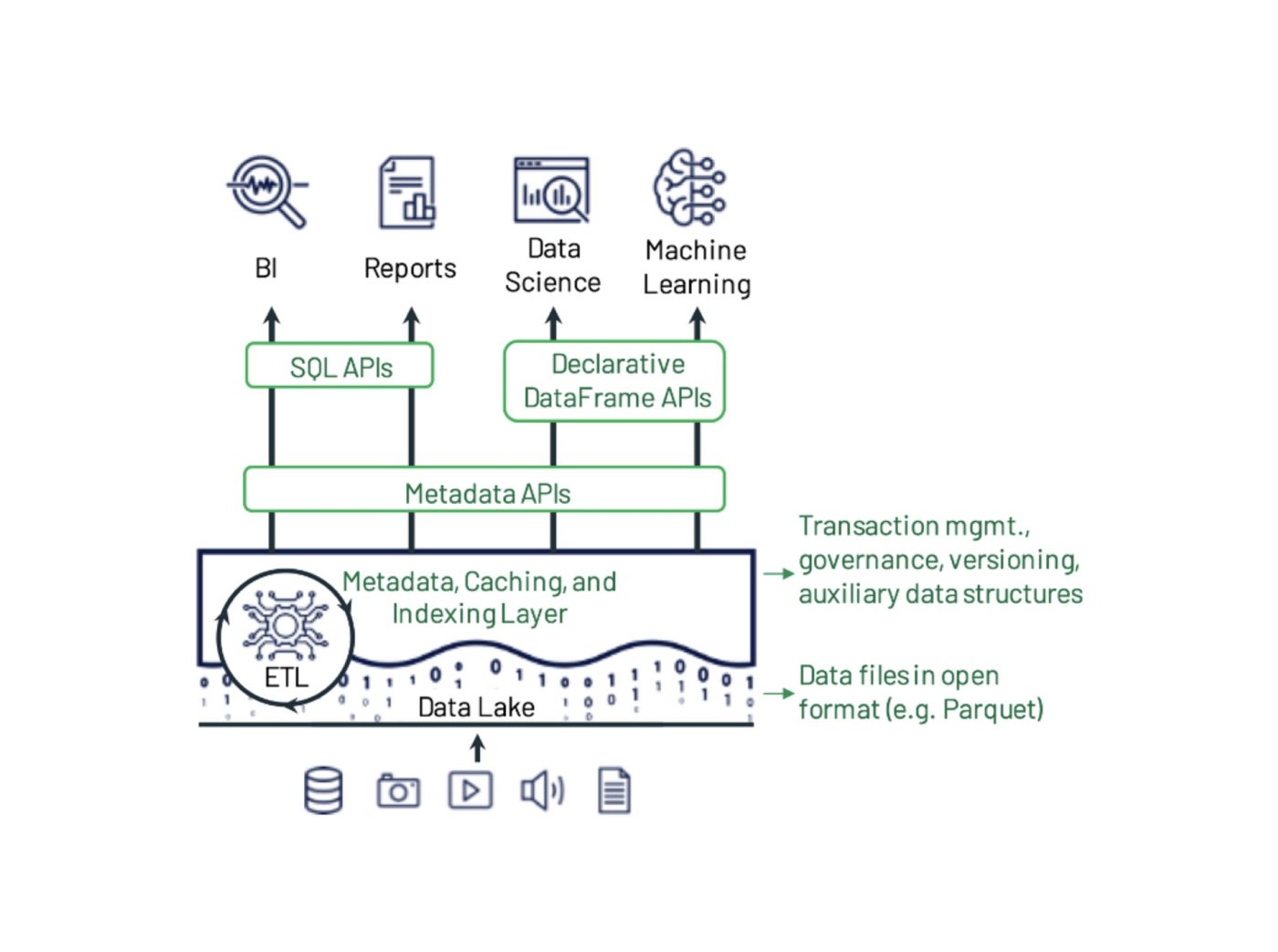
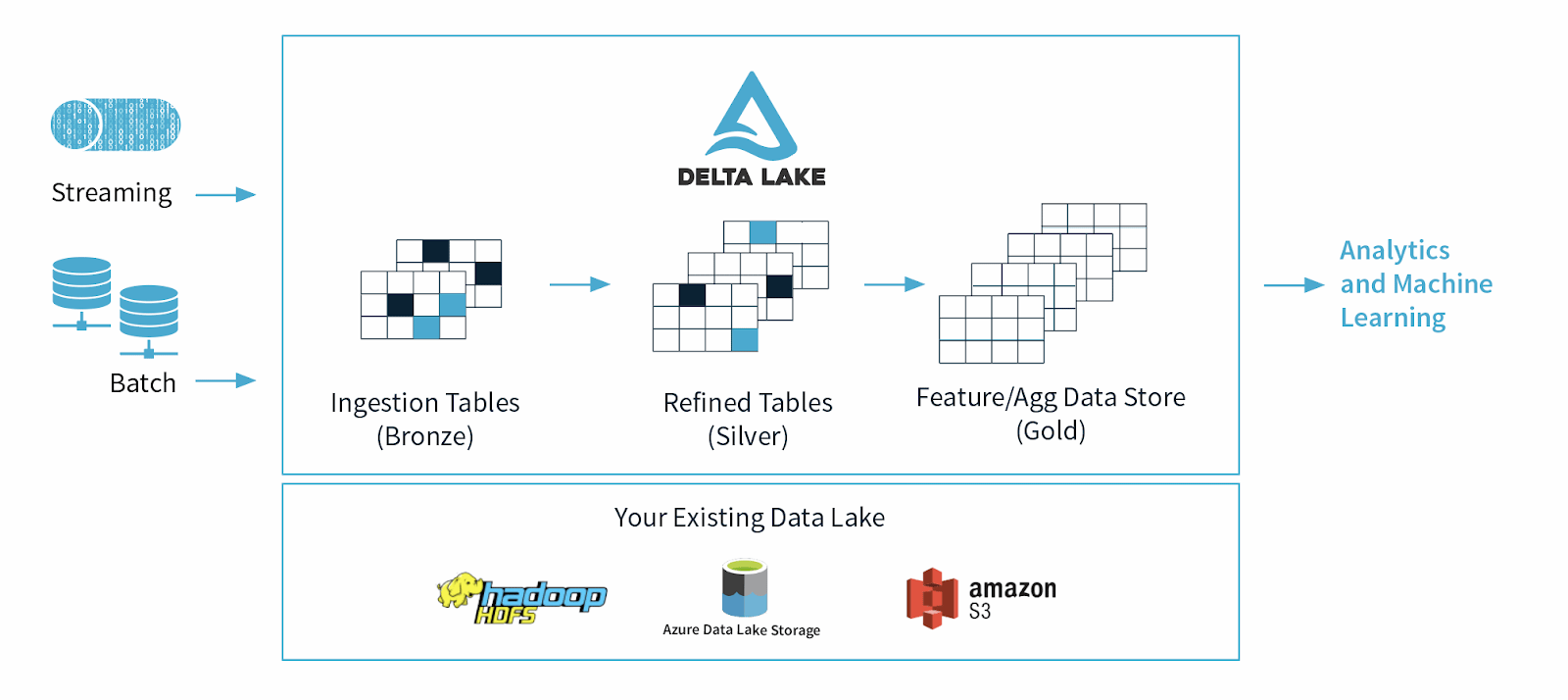
Delta Lake ist ein Open-Source-Daten-Storage-Framework, das entwickelt wurde, um die Zuverlässigkeit und Performance von Data Lake zu optimieren. Sie behebt einige der häufigen Probleme, mit denen Data Lakes konfrontiert sind, wie z. B. Datenkonsistenz, Datenqualität und mangelnde Transaktionsfähigkeit. Ziel ist es, eine Daten-Storage-Lösung bereitzustellen, die skalierbare Big-Data-Workloads in einem datengesteuerten Unternehmen verarbeiten kann.
Delta Lake – Ursprünge
Delta Lake wurde 2019 von Databricks, einem Apache Spark-Unternehmen, als Cloud-Tabellenformat auf Basis offener Standards und teilweise Open Source eingeführt, um häufig angeforderte Funktionen moderner Datenplattformen wie ACID-Garantien, gleichzeitige Umschreibevorgänge, Datenveränderbarkeit und mehr zu unterstützen.
Was ist der Zweck oder die Hauptnutzung von Delta Lake?
Delta Lake wurde entwickelt, um die Nutzung von Data Lakes zu unterstützen und zu verbessern, die riesige Mengen sowohl strukturierter als auch unstrukturierter Daten enthalten.
Datenwissenschaftler und Datenanalysten nutzen Data Lakes, um wertvolle Erkenntnisse aus diesen riesigen Datensätzen zu bearbeiten und zu gewinnen. Während Data Lakes die Art und Weise, wie wir Daten verwalten, revolutioniert haben, bringen sie auch einige Einschränkungen mit sich, darunter Datenqualität, Datenkonsistenz und, das primäre, einen Mangel an durchgesetzten Schemata, was es schwierig macht, maschinelles Lernen und komplexe Analysevorgänge an Rohdaten durchzuführen.
Im Jahr 2021 argumentierten Datenwissenschaftler aus Wissenschaft und Technologie, dass Datenpools aufgrund dieser Einschränkungen bald durch „Lakehouses“ ersetzt werden würden, bei denen es sich um offene Plattformen handelt, die Data Warehousing und erweiterte Analysen vereinen.