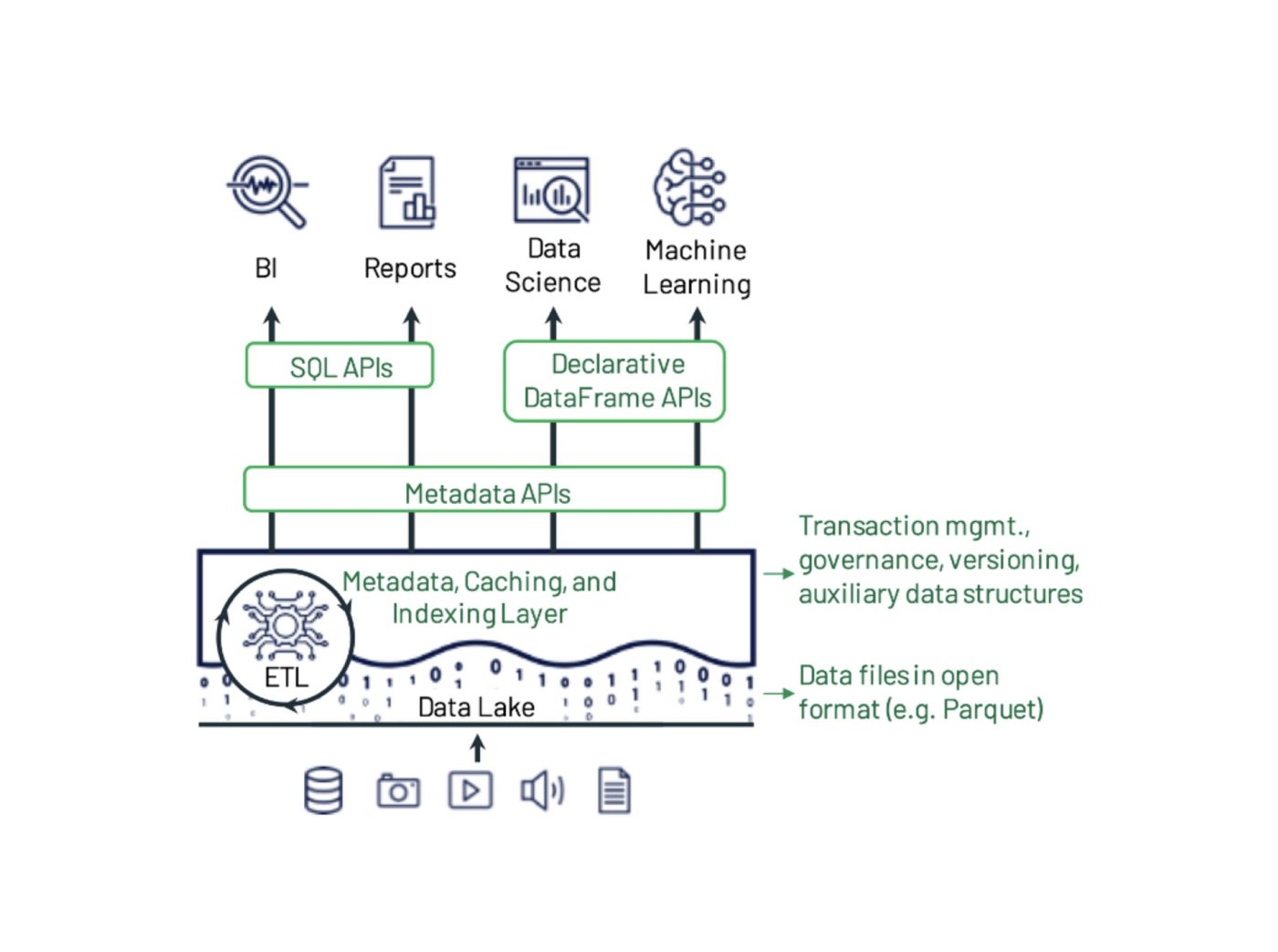
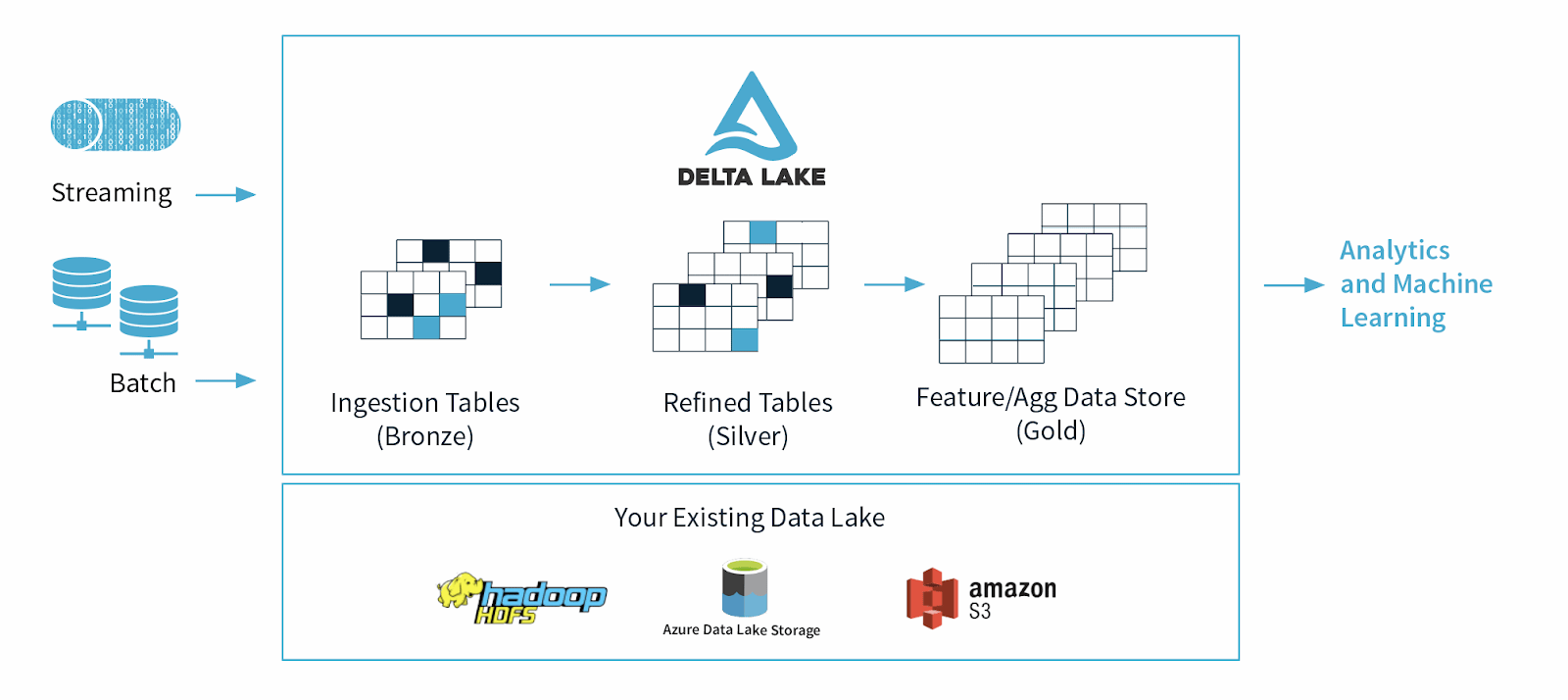
O Delta Lake é uma estrutura de armazenamento de dados de código aberto desenvolvida para otimizar a confiabilidade e o desempenho do data lake. Ele aborda alguns dos problemas comuns enfrentados por data lakes, como consistência de dados, qualidade dos dados e falta de transacionalidade. Seu objetivo é fornecer uma solução de armazenamento de dados que possa lidar com cargas de trabalho escaláveis de Big Data em uma empresa orientada por dados.
Origens do Delta Lake
O Delta Lake foi lançado pela Databricks, uma empresa Apache Spark, em 2019 como um formato de tabela em nuvem desenvolvido em padrões abertos e código parcialmente aberto para dar suporte a recursos frequentemente solicitados de plataformas de dados modernas, como garantias ACID, reescritores simultâneos, mutabilidade de dados e muito mais.
Qual é a finalidade ou o uso principal do Delta Lake?
O Delta Lake foi desenvolvido para dar suporte e melhorar o uso de data lakes, que contêm grandes quantidades de dados estruturados e não estruturados.
Cientistas e analistas de dados usam data lakes para manipular e extrair insights valiosos desses conjuntos de dados enormes. Embora os data lakes tenham revolucionado a forma como gerenciamos os dados, eles também apresentam algumas limitações, incluindo qualidade dos dados, consistência dos dados e, o principal, falta de esquemas aplicados, o que dificulta a execução de aprendizado de máquina e operações de análise complexas em dados brutos.
Em 2021, cientistas de dados da academia e da tecnologia argumentaram que, devido a essas limitações, os data lakes logo seriam substituídos por “lakehouses”, que são plataformas abertas que unificam o armazenamento de dados e a análise avançada.