00:05
Hello and Welcome to Tech Fest 22. My name is Chris Sprague and with me is my good friend and alliance partner Mark colon. How you doing today? Mark? I'm doing well, Chris how are you doing? Very good excited to be here and doing a session for Pierre Accelerate Tech Fest 22 With You?
00:25
Yeah, likewise, what are we talking about today? Yeah, So today we're going to talk about the ultimate VM storage architecture and take a look at a few different ways when you think about this, when we're architect in a solution. So my name's Chris Sprague as I said, I'm a field solutions architect for modern data
00:44
protection at pure storage where I focus on all things data protection and get to work with our great Alliance partner VM here Mark, you want to say a little more about yourself as well? Yeah. Thanks Chris, as chris mentioned, my name is Mark Poland. I am the global solution architect for vegans. Pure Alliance work on co innovation projects and uh technical support
01:09
of go to market project. Excellent. Thanks Mark. So let's get into what we're talking about today. So we have a small short agenda here for you to get through um we're going to set it up the scenario here is you just got the call, the company wants to build the ultimate VMro architecture leveraging,
01:31
the best that both Pure and VM have to offer. So we're going to look at this in a few different ways. Right. Some considerations here. We're going to take a look at availability. We're going to take a look at security and then also the architectural choices you may make around those anything to add their Mark. No, no, I you know this this scenario could be to prevent ransomware,
01:54
it could be that you've had a ransomware incident and now you want to create this ultimate architecture to make sure that the next time it happens that uh there's no consideration or no need for consideration of paying the ransom, you've got everything in place. Two recover your data from backup a great point. Be able to
02:21
recover without paying that ransom. Right, alright. So let's get into it. The first piece that I mentioned there was availability and as part of availability we're going to look at our pos RTO s Right, so recovery point objectives, Recovery time objectives, those service level agreements or sLS will throw another term out there that are getting smaller every day.
02:46
And we want to be able to meet those um Mark, you want to tell us a little more about, you know, what an R P O versus R T? Oh, maybe yeah. So when I think of recovery point objective, I I think of the freshness of the data. So how recent is my uh my recovery point so that if I need to recover that I can actually recover from that and then
03:16
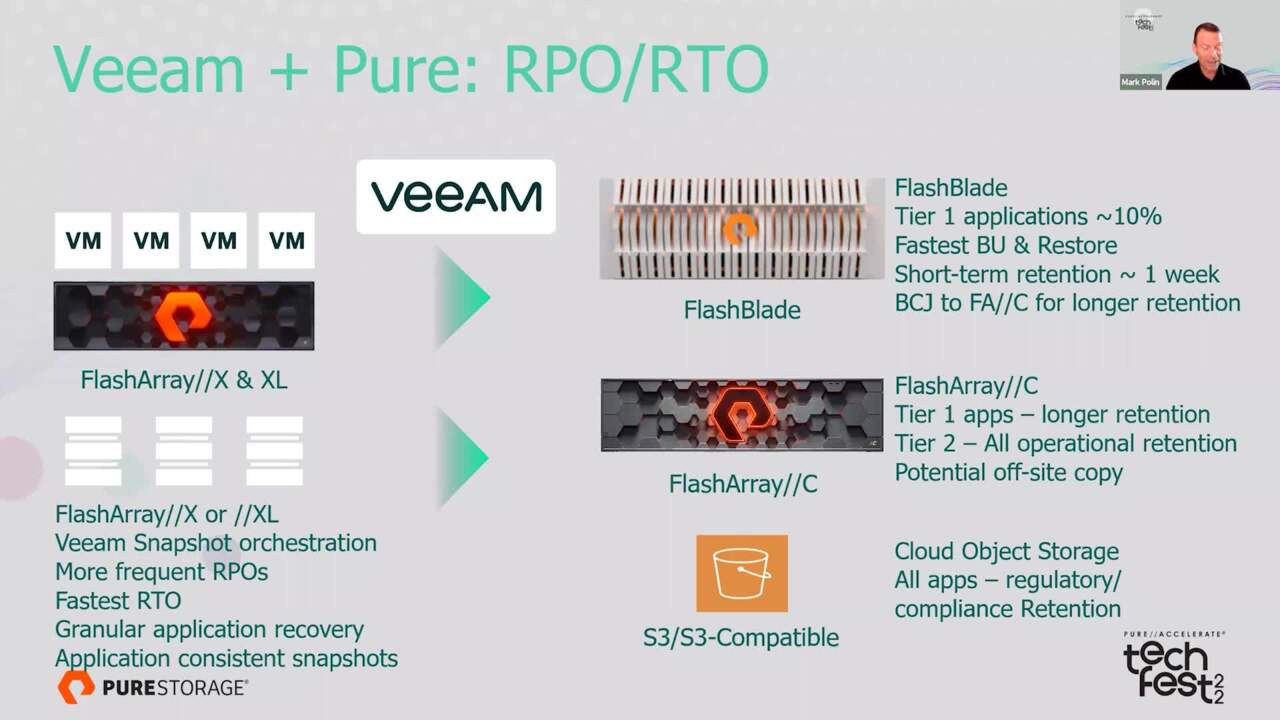
recovery time is how long does it take to recover that particular recovery point back into production. So that's how those two uh fit together. Excellent. Just to kind of set up the, what we're looking at here before we dive in deep. We've got really, I would say a typical environment but maybe this is actually the
03:39
ultimate environment with pure and VM so we we've got a flash array X or an Excel in production on the left and then we have options for VM repositories, backups to doing our data protection on the right, any anything else Mark? You think we need to set up here before we get into it? No, I I really, you know the way I think of it is production on the left.
04:05
So I'm running, let's say it's a, you know, a V sphere environment with the flash array X or Excel is my underlying storage. And then on the right, I I tend to think of that as backup storage. Right. So where am I going to land those backups and uh and keep that retention. Perfect. So let's start on the left side.
04:30
We're going to start with the production well look at flash ray, X or X L and what we look at for availability and production. So first piece vM snapshot orchestration, great, great feature that VM And pure enabled together. So that VM has full control if you would of your primary storage array snapshots and can do retention on those Mark.
04:57
You want to tell us a little bit about how we do that. What what enables that for us? Yeah. Thanks chris so VM and pure work together to create this integration on the VM side, you've got what we call the universal storage, A P I or U S A P I and Pure then wrote a a storage plug in for that for the flash array.
05:25
So what that gives us because it's the combination of Pure and VM now is for VM to be able to orchestrate operations over on the flash array, X or X L. And at a basic building block that could be something as simple as VM orchestrates a snapshot for backup from storage snapshot.
05:53
But what we want to talk about here is that that really that next level uh capability with VM snapshot orchestration. So let's say at eight o'clock at night I run my back up and I actually do back up from storage snapshot. That's a good choice to to do. But Between eight PM and the next backup cycle at eight p.m., which is pretty typical for most of our customers.
06:21
A daily backup. I want to make sure that I'm protected throughout the certainly throughout the business hours, if not all the hours of the day. So what the VM administrator can do and this is key because it's, you know, all the data protection will be centralized for that VM administrator persona. So they can create a job using the
06:47
tools that are completely familiar to them. I to orchestrate snapshots that will be kept right on the production flash arrays. So it's what we call a a snapshot only job and you can do these, you know, hourly snapshots is entirely reasonable, several times an hour can
07:12
be. And and chris maybe, you know, mentioned about your snapshots and you know, the, you know, how fast they're created, how space efficient they are. Yeah, absolutely. Thanks. Um great, great explanation. Yeah. And what makes that like you said even better
07:31
is just the the purity snapshot creation, there's no overhead. They happen immediately on creation, they take up no extra space. It's simply metadata pointing towards all the data. Right? For your point in time snapshot. So when VM can kick those off there, there's no no hesitation that it's gonna
07:54
affect your array. Right? And furthermore going a step further what we're really talking about there is more frequent our pos right? Getting lower and lower recovery point objectives, meaning like you said, maybe I'm running a backup once a day, but I could be taking snapshots hourly or even a shorter time frame.
08:13
Right? And the reason those really bring down our our pos is with that VM integration, we can also restore from those those snapshots as well well. And Absolutely. And that's what on the flip side. Right? So now you've got more aggressive recovery point objectives along with that when you're
08:35
doing snapshot orchestration come more aggressive recovery time objectives because you don't have to move the data from the backup storage back into production or even, you know, do any kind of instant recovery. You're talking instant recovery from backup, You're talking about potentially instantly recovering or doing granular recovery right from the production storage. So you get true production performance for
09:06
these operations. Yeah, great point. You know, it is the fastest rto bringing a snapshot back. Just a metadata operation, a few pointers that happens almost instantly so that can be very fast. But I like what you said as well, even if we needed to restore like VM can crack into those snapshots and restore an individual item.
09:27
Right? That's more like a restore operation than just returning a snapshot. But it's happening from your production snapshot so it is going to be much faster. It's their local right? You're util utilizing those snapshots and we can do that granular application recovery. It really in all my years working with these solutions is my favorite part right to be able
09:50
to gradually recover from a snapshot. Having that granular application recovery is incredible. Yeah. And you know, the other thing to mention, if you look at most likely recovery scenario in the data center, it's not a piece of equipment dying. It is likely some kind of maybe corruption
10:13
or more likely a user did something that damaged or destroyed some of their data. So the data set that we're looking at to recover from those types of events is typically a database, a file, maybe a handful of those things from, you know, you know, when I think about, oops, I've been working on this spreadsheet for the
10:41
last two days and I accidentally overrode it and hey, can you get it back, you know, from an hour ago when I did the uh the unfortunate event, yep. Exactly. So taking that even one step further application consistent snapshots, right. VM can actually qui es or make those snapshots
11:05
application consistent for us and Mark, you want to tell us what kind of benefit that that gives gives us? Yeah. Well I mean the bottom line here is that you're gonna improve recovery ability by having those transaction only consistent or application consistent snapshots. So all the, all the transactions that were in memory get flushed out before the snapshot is taken, giving us that consistent
11:34
state. So when it goes to recover it doesn't have to do any cleanup process. Very nice as opposed to say crash consistent where we may lose transactions that were in process. Right well and yeah, so that that affects your recovery point objective and then on the recovery time objective,
11:54
if you had in flight transactions, the, the, you know, the application that you're working with might need to do some cleanup before it can bring that service back online. Excellent. So let's take a look at um we're going to talk about flash blade now and our our first tier of backups. Right. So And there we go.
12:21
Tier one applications. Right. This flash blade is built for this fastest restore backup and restore speed. Right? So we look at it as a tier one application might be approximately 10%. It's what we generally see as far as Tier one applications and that businesses want to protect its somewhere in in the 10% range of maybe their total uh,
12:43
VM count, write anything you want to mention their mark on tier one out. Just really that, you know, when we're talking tier one applications, we're talking about business critical stay alive applications. So it makes for a lot of organization, it makes sense to put those on the fastest platform.
13:05
Right? It's not it's not a black and white decision with pure and VM that I have to, I have to go all in with anyone platform. I can, I can use leverage the flash blade for my Tier one backups. I can leverage the flash blade for other workloads as well, You know, machine learning type stuff. But I'm just going to carve out some of the
13:30
space on that for my the backups that need the absolute fastest backup time and the absolute fastest recovery time, which as Chris mentioned, you know, is somewhere in the, you know, 10% range of overall applications and data. Great couple of points. You you mentioned there one flash blade is uh, our scale out architecture. So it really does work well for multiple
13:56
workloads. Right. It doesn't have to just be your modern data protection platform to land backups. It can do a I analytics, high performance computing as well on the side, um, without any performance degradation. So I like that. And of course if you feel you know some, there are some businesses out there where maybe everything is a tier one app,
14:20
right? Or everything is very critical. You can put it all on here. We just generally see there is many times customers have levels of those applications like you said those business critical apps that I need to bring right back right away. A lot of times. Those are databases, things like that. I see out there,
14:41
That's going to give us the fastest backup and restore speeds. Right. This is what flash blade is known for. I mean this platform is used in high performance computing arenas out there. It's absolutely very fast to restore and this single in this single chassis, I can get upwards of 15GB per second of restore speeds, incredibly fast.
15:02
Right? We want to talk about retention. We uh, you know, we, we talked about retention on maybe our tier one apps and what we're looking at their mark. Yeah. And that's a really good question because again, getting back to what we were talking about just a moment ago, it's not black and white all or nothing. It's what makes sense for this platform.
15:27
And so where I'm getting the, you know, the highest backup performance, the highest restore performance, maybe I only deep those things which I'll call operational retention. The things that I would want to actually restore back into production as fast as possible, which we're gonna go with about a week. Right. I mean if you think about an oracle or a sequel
15:52
database, that's, you know, more than a week old, I'm probably not going to restore that back into production. I probably actually only ever want the most recent backup and the only reason I would go back prior to that, so two days ago is if something happened to that uh, that back up and I needed to go back to a further recovery point.
16:16
But uh, there's no requirement here to keep longer retention on this. Use it for what it's good at and that is performance. So keep the short retention on that platform. But is you, is, we'll continue on with this conversation. We're not saying only keep seven days of retention on this. We're just saying Put the seven days on the,
16:42
you know, the, the highest performing platform or tear of stories. Yeah, great point. The other thing we can do for that longer retention. This is called a backup copy job in VM where we take a backup, do a copy of it to another another platform for that longer term retention. Right, mark. Yeah. And so we're leveraging the backup that's
17:06
already sitting on that flash blade. And we're just saying grab a copy and move it over to the flash of racy for longer retention. Where the flash or a C. Is that capacity optimized platform? No requirement to go back to the production environment and grab more data? We've already got all the data sitting on the flash blade. It's just move it from that uh you know,
17:33
the flash blade over to the Flasher, Hc. Speaking of which? So let's talk about the flash racy and Mark alluded to this here. That flash racy is our capacity optimized all Q L C a flash array. Right. So it's really built for capacity but still gives you the performance and consistency of flash.
17:55
Right? For being able to restore. Uh And so we can use this platform in a in a lot of ways as well. So as we talked about our tier one apps and longer retention and so what maybe what maybe we're looking at here, Mark, for when we talk, when we say longer retention, you know, it's a good question. It's how long do you want to keep your total on
18:20
premises retention? And you know, we talked about for operational retention maybe that's, you know, a couple of weeks to a couple of weeks, but I would say that, you know, total retention that you want to keep on premises from, what I've seen from customers is probably somewhere between a month and at the most three
18:43
months. Exactly. So thinking right along the lines I am, this may be where you have your short term on that flash blade and then we're going to keep maybe our, our gFS our grandfather, father son long term, right, we'll put some weekly backups, maybe some monthly's like, like you said up to a, you know, a quarter, three months,
19:06
I have some, some seen some push it out to to a year, but this is where I would um keep those longer term roll ups or folds. Right? Weekly, monthly. And then I think you, you mentioned it perfectly really, the retention period is how much do you want to keep on prem.
19:26
Right, so you still can have good good speed of restores done. So Tier two apps. So this could also be our platform for all Tier two apps to go all operational retention. So where we might put tier one on a first platform for really high speed recovery, we can put all of our tier two apps on the flash racy and here we're talking about all
19:55
operational retention. Right mark. So we'll have our, our weeklies or are, you know, a couple of weeks of daily retention points every nightly backups. But then this would also be where we keep those weeklies and monthly's for these types of apps, correct? Yeah, exactly. Right. They don't have Tier two Plus apps.
20:15
Right, it might even be tier three apps just don't have that requirement for high speed. So we still get really high speed out of the flash racy. I don't wanna uh disrespect that platform. It's just uh, as you mentioned, it's capacity optimized as opposed to the flash blade being uh performance optimized. So it is a really ideal storage
20:43
platform for all the retention for the Tier two plus apps and that longer retention for the tier one app. Exactly. And lastly kind of the last thing I want to mention here is this could be a potential offsite copy. So we'll get more into this in in the next The next bullet point and talking about the 3-1 rule and those things but this
21:13
could be the backup copy job to this flash way. See this flashlight can see could be sitting in your secondary site for instance is kind of what I mentioned here and we talk about getting things off site. So this could be on prem in your main dataset with with a flash blade or as the direct target. It could also be at a second site where you do backup copies or just send your backups
21:36
directly to that second sight. Exactly. Let's talk about cloud or object storage options that we have with Demon Pure here. So Mark, you want to go ahead and talk about sending, you know, we're going to send all apps here a lot of times we look at for regulatory or compliance retention. Wanna tell everybody kind of what that means.
22:00
Yeah. So when I talk about operational retention, I that those again those are the things that I would want to actually or potentially restore back into production. Right? So in my mind I want to keep all that data on premises for the fast, fast recovery but most organizations certainly compliance centric customers like
22:24
healthcare and financial but I think it's even, you know gaining with with our customers uh they are under whether it's external compliance and regulation from like governmental bodies or whether it's, you know, something that the their organization created as regulations but they need to keep this data around the backup data for an extended period of time. Now that could be as little as six months could
22:54
be as much as 21 plus years I've heard for, you know, some organizations and it, you know, going with the most cost effective storage here, object storage and cloud object storage from potentially from the hyper Scaler makes a lot of sense for this data that if you think about it it's write once read almost never.
23:25
I like that term. I was going to say this is that data that you're basically required to keep and you hope to never restore. Right. The other point they're just, you know, if if this data can be used for discovery with legal events like discovery and one thing to keep in mind is if a discovery event happens and you need to access
23:50
this data needs to be accessed it's not going to be your company's I. T. Folks that are accessing it. It's probably gonna be some legal I. T. Group that's accessing it. So you know it's it's really it's another step removed from that day to day operational stuff. Great point and then another point here to
24:19
kind of just sum it all up and the big rule that You know guides all of our data protection the 3-1 rule and while I'm I'm intimately familiar with this mark I think being from Vienna you're probably the best to to give us the explanation here. Yeah thanks chris and you know this is a great setup for this particular rule. The 3 to 1 rule is a very good recommendation for your
24:48
backup. Three is three copies of your data. So in in this scenario would be one production and two backup copies. The two is two different media types now you know that could be flash, it could be object, it could be you know flash blade, it could be flash or a c right again different media types and then finally the one
25:16
is one offsite copy. Just so in case something really bad happens at the primary site I can recover from another site to potentially you know somewhere else. Yeah perfect. The next piece we want to look at our second bullet point, there was security and so we are going to look at the security from mutability everywhere, front end to back end with pure and VM this this is great.
25:46
But you know why is the mutability important today? Ransomware is such a big, a big topic, right? Not even a topic. It is, it's a business out there for a lot of people and making our backups or any of our data immutable so that that data cannot be changed or taken from us is very important today. So we're seeing a lot of customers out there
26:11
battling ransomware and having immutable data will protect you from that and like we mentioned earlier, you don't want to pay that ransom. That's really what this is all for. So we'll start in production again on the flash ray X inside over there. We have what pierre calls safe mode snapshots and we can do that of our production volumes.
26:33
So what safe mode is is it is an array wide kind of think of it as an overlay. We take snapshots. I've already mentioned what those are safe mode protects everything on the array from man. Manual eradication. So you cannot permanently delete anything. Not even um the admin, not if you have admin credentials or root credentials, you still will not be able to
26:56
delete these. So attacker comes in, say they encrypt your volumes, they go delete snapshots. They will not be able to fully eradicate those snapshots with safe mode on so you can bring all of your production data back. So moving over to the flash blade side. Now we'll talk about back on the the back
27:17
upside same thing with flash blade which is our file and object platform. We utilize safe mode snapshots as well of backup repositories. Now the nice thing about this is you will be taking VM backups with your VM backup retention and then we can snapshot those backups. So we don't again, I don't need a lot of days of safe mode here.
27:40
I can set the number of days probably just a few days to know that an attacker has got in and maybe encrypted my volumes or tried to delete all my data because each time we take a snapshot I'm going to have all my VM retention. So that week or 14 days that we talked about will actually be kept in your snapshot when you restore it. You'll have all that VM retention to go back and restore do all the V magic with
28:06
moving on to flash or a C. We again have safe mode, snapshots. We can do snapshots of VM backups. Be similar to what I just mentioned on flash blade, you'll have all of your VM retention within those snapshots. Again, you just need safe mode and snapshots long enough to notice that someone got in and did some nefarious things to your data.
28:30
Right? But this is not, we don't want to think of it as our retention period and we don't need 30 days of safe mode or 30 days of snapshots. We have that in the VM backups and even more so on this flash or a C where it might be our longer term retention. You could have three months of back ups here. So every snapshot your take is going to have all that retention,
28:51
any any thoughts on that. No, no, that's a really good point. 11. Just one point to mention this snapshot capability is outside of our snapshot integration over on the production uh flash array X and XL. Even the VM orchestrated snapshots right. With that array, wide safe mode capability. Those will be protected automatically by safe
29:20
mode. But over on the back upside we're not talking about actual integration code happening. We're just saying were, you know, utilize the tools available on flash blade and flash array to take these immutable snapshots safe mode snapshots of the the backup repository data. So if you know the criminals try and damage
29:48
or destroy that, you can get it back again without paying the ransom furthermore, with flash racy we can also do beamed hardened repository within mutability blast ray C is our block based array. And so we can do both of those in conjunction. And so you can do in mutability with VMS hardened repository and have safe mode as well. And and really build out a defense in depth
30:17
strategy. Yeah, this is a belt and suspenders approach rick van over one of our chief technologist, he calls this the demon pure double play. Right? So you're you're you're you're making extra sure that you've got these things protected. And the hardened repository is effectively a set of guidelines like a
30:43
recipe from VM on how to lock that platform down. Now you're going to have a physical machine with that flash or a C so that we can truly harden this down without letting somebody in through a VM console. Um And then what we're going to do for a mutability is I think if it is software based on mutability because it's really turning on the mutability at the Linux file system level.
31:11
Yeah. And and that's excellent. Like you said, really puts that double play in there really gives us a lot of security and then we'll wrap it up again with our cloud or object storage talk. And really what this brings is some native object locking mutability. So as three has that capability. Natively that VM can utilize.
31:35
And this is great because it's really as simple as when you're setting up your backup job as a checkbox, when you want to tear out to cloud or object to make it immutable, right mark. Yeah, exactly. I mean when you create the bucket, you gotta set it up with object lock in compliance mode so nobody can go in and and modify things. But once you've done,
31:58
you know, set up that bucket, then it's just point VM scale out backup repository over at that S three bucket and checkbox do I want a mutability? How many days do I want the mutability on that and back to chris's point. It's it's important to think that I've got all my retention there. So when I think about a mutability, I need to separate that from my thinking about retention,
32:25
right. I want to set a mutability uh for all of my retention but I want to do it for a short number of days. So I'm not keeping these objects around unnecessarily long and therefore, you know, making my my backup storage unaffordable. Great point. So just to um summarize this whole slide,
32:47
right. We called it the mutability everywhere we can now go from production on the left of this slide where we have safe mode snapshots protects you from um everything right. Even even rude access, you're protected in your production and then onto the backups which we can protect with safe mode furthermore viens hardened repository of mutability.
33:10
And then if we actually send those off to the cloud we can get that object lock compatibility. So not only can we protect everything within our data center, maybe a couple of data centers on prem we send it off to the cloud and we still have that really uh good mutability feature with that. Talking about the choices and the pieces we have there for availability and security.
33:33
Let's talk about some of the architectural choices, we're going to need to make a Mark when we deploy this. So we're gonna start with the VM backup server. So some of the choices we have there physical virtual cloud with some of the ideas we came up with um Mark. Why don't you talk us through some of those?
33:53
Yeah. So if you know with the backup server, um you can put it pretty much anywhere you want. But what makes sense for for your environment? Right, putting VM backup and replication server on a physical server. If you've taken the approach of I want to put everything on one server that all in one appliance like approach where I'm going to have all the components,
34:21
the backup server, the backup proxy, the backup repository. That is probably a good argument for putting it on physical uh for virtual. Uh if you're not going with that approach, then a virtual uh implementation of VM backup and replication can make a lot of sense and really extending that virtual capability is is really talking about the cloud because,
34:50
you know, if I if I'm going to have a virtual machine doing all the command and control, which is what the backup server does, does it make sense to put that in my production data center, does it make sense to put it in my disaster recovery data center or what I'm starting to see as a trend is organizations putting that in a Hyper Scaler, like an AWS or an Azure as the machine? Uh a cloud
35:18
virtual machine. So that if any of my sites go down, I've still got my command and control running uh in an off site location. Great points. So what what do you think we're talking ultimate here, Mark, what what do you think is the ultimate out of these choices? To me? I think putting it in the cloud is the ultimate
35:39
choice because uh it gives you capabilities that you wouldn't have with it, putting it and you know, it's not a virtual or physical uh conversation. It's really, you know, what's going to be the give me the highest level of availability possible if something bad were to occur. Yeah. Ok. Yeah. Makes makes a lot of sense. I can get to it from anywhere.
36:06
It's a lot less likely to go down out there. Right. All right. So with that let's move on to talking about scale out repositories and some choices there. So, uh physical or virtual again is going to be our first choice. One thing I like to point out about scale out repository and why we have it.
36:28
Mhm diagrammed this way is a lot of times when I when I'm talking to customers, we think of the repository as the actual disks and say like our flash array or flash blade. But in reality the scale out repository is a VM service running on a server somewhere. Right. So when we're talking, you're saying, what do you mean physical or virtual?
36:49
Um because I'm not talking about the storage, I'm talking about a server we're going to set up. Right. So you wanna maybe go through those options are physical versus virtual. Yeah. And I think, you know, it pretty much follows the same conversation that we just had about the backup server. If I'm if I'm doing a um, if I'm doing that all in one approach,
37:13
Yeah, it makes a lot of sense to do that on on a physical platform. Uh, if I'm, you know, going with uh, you know, something other than that. Right. Maybe I'm going with SMB or NFS storage like with a flash blade, then, you know, it doesn't really make a lot of sense to put it on physical or can I, you know, get everything I need with virtual.
37:40
So, uh you know, you've got certainly a set of choices there. If I'm using hard and repository, then I'm gonna go physical, but it's nice to have that choice. Uh, and that's one of the big benefits of going with them over the other options out in the market today because you do have that choice. And of course you've got the folks uh,
38:06
at pure and add VM and our trusted partners that can help you easily make those easily and quickly make those decisions, yep. Yeah, I think uh you know, you hit that very well, another kind of deciding factor is how much of this traffic do I want off my land network. Right. If I'm gonna go physical with ice cars,
38:30
your fiber channel, um I could get, you know, I have my own dedicated backup network, even virtual, I could do something like in gastonia, scuzzy if I if I really wanted to. So the next option, their Windows versus Linux. Okay, so now I've picked myself the physical box, um I'm going to install windows or Linux and I guess what I would say here is generally this is kind
39:00
of a decision on what does your shop? No, the best. What are you most comfortable with? Right, I wouldn't want to try to, you know, put a square peg in a round hole, you know, uh now the one the one really deciding factor. If we're going to use the hardened repository, of course we'll want to use Linux in that case today.
39:20
But other other than that, because that brings some great capabilities other than that. Generally, if you're, you know, window shop and you're familiar with that, stick with it and vice versa with Linux. Right. What, what are your thoughts on that mark? No, I'm with you there, it's uh, you know, this is not something where you want to be taken on a science project.
39:39
If you, you know, if you're predominantly Windows go with Windows, if you're predominantly Linux go with Linux uh and let that be the deciding factor. And then last one here. Block versus file. Right. And I will mention um there's a couple of reasons you would be required one way or another.
40:00
So if we're going to flash blade, it's appears fast. File and object platform. So you will need to do file something preferably nFS. Again, depending on if your windows or Linux, you might choose NFS over Smb. NFS is the ultimate in this case.
40:17
Um But then our ray, you know, Flash ray is a block block platform. We go with block that way we can get our best performance, we can use the hardened repository feature and I think even a step further than that we go block, we're going to want to use one of those block cloning technologies. Right. Mark, like R E F s or X Fs?
40:39
Exactly right. It contributes to the data reduction actually. Uh you know, rather than calling it de duplication, I I have heard the block cloning file systems called pre duplication because it never creates the duplicates in the first place. Uh So it's a it's a space saving technology, it doesn't interfere with performance or reliability.
41:03
Uh To me in the ultimate architecture, you definitely want to leverage that if you're going with blocks north. Excellent. So you mentioned that the ultimate architecture if I had to pick out all of these now, they all work Great. We can architect it how we want, but if I'm going with that ultimate architecture here for a scale out repository, my ultimate would be physical.
41:26
So we can get that hardened repository and block with X. F S. I I got to completely agree with you. Good good. All right, so moving on we are going to will end this architectural discussion with the backup proxies and the choices we have to make their which again are going to be physical and virtual.
41:51
Um We may actually we even have some choices on on protocols which I didn't put here. But mark you want to talk us through what you see as ultimate for backup proxies. Yeah. So keep in mind that the backup proxy we affectionately call it the data mover so it grabs the data from the virtual the virtual machine data store or the physical machines that are being backed up with agents.
42:18
It can grab that from the you know, the physical uh storage associated with them. Think database servers is what I typically think of in that regard. Uh and it transports that over to the backup storage. It does a couple of optional things in that process as it moves it. It can do uh you know, compression, it can do de duplication and it can
42:45
encrypt the data as well. So you know, the proxy really is probably the the the heaviest working component within the VM infrastructure and uh you know you can do it on physical you can do it on virtual. now when we talk about the production storage that's gonna drive some of our choices a little bit because if it's fiber channel attached production storage it's got to
43:17
be if you and if you want to take advantage of backup from storage, snapshot and and that type of integration then your choice is going to be physical. But if you're using I scuzzy it could be physical or virtual in that case, correct? Yeah. And that's your your mind went right where I I went right. There are some choices about protocols,
43:42
connectivity probably just going to follow what you're already doing in production. Right. Um like you said I want this on my my sad network if possible I get the best integration and I can get all of that traffic, you know, off my off my stack, my VM ware stack in this case. So I think both choices I've seen both used a lot, you know,
44:05
there's a lot of virtual like you said I could even go virtual proxy and do in guest I scuzzy and get some of that integration but just you know, be aware it's still all flowing through your virtual stack. Right. Where if I go physical, I can get that completely off there. Yeah. The last point that I will bring up and again I've seen it at enough customers that I can refer to it as a trend is to do a
44:31
combination of physical and virtual. It gives me that additional level of redundancy. And for the small virtual machines, the 100 gigabyte virtual machines that don't change a lot. Right? They won't benefit as greatly from the backup from storage snapshot as those large, very highly transactional
45:01
machines will so I can do a combination of both. And it actually again, it's that belt and suspenders approach, yep. Yeah, that's that's a great that's a great point. I actually wanted to to make that, you know, there's a couple of icons for backup proxies in here and there's a reason, right? Probably want a second one for redundancy.
45:22
And then I always like having that additional virtual one uh in in you know in case it's my fallback or for even virtual restores. They help a lot. So good point. Alright. I think I think we we covered that the ultimate peace. Is there any, don't you think we missed Mark? No, I think this is a pretty comprehensive, you know, conversation around the,
45:49
you know, your choices. Perfect. Yeah. So as we we close this out, uh kind of a call to action to end. We discussed a lot of stuff here. Maybe even deeper than we hoped to go. But there are a lot of terms we talked about and other um other solutions that we didn't dive into here. This was really just about the ultimate pieces
46:10
in the selections. So there's some additional sessions going on indestructible backups with VM and NPR Flash ray is being done by some of our friends and colleagues that up. You're gonna go deep dive, maybe do some demos and then Mark, you yourself have a Pure and VM you're talking about our snapshot integration in depth that we mentioned here multiple times.
46:33
Yeah. And not only do I talk about what's available today that's with our universal storage. Api wanda. Otto I also give a sneak peek on what's coming in. Universal storage. Api to Dato. And I have to mention that pure storage has been victims development partner with
46:54
the A P I project itself, U S A P I to Oh, so been a great development partner and or when we released version 12 later this year, Pure will have that first U S A P I to Dato uh, plug in to be able to take advantage of those. So check out and see what's coming in, the next release of the universal storage. Api Yeah,
47:22
thank you for that. Mark, I mean we are pure are super happy to be that that engineering partner on, you know, the universal storage, A P R A P I and our plug in two point oh, which is just going to bring more great integration features. So make sure to check out Mark's session on that. And with that, thank you all for sticking with
47:42
us. We hope you have a wonderful tech fest 22 and thank you so much mark, this has been a lot of fun. Thank you chris this has been a great time. Thanks everybody.